.png)
Does Muon improve regulatory DNA learning? Part 1.
March 5, 2026 · Viraj Doshi
Highlights
AdamW = Adam with Decoupled Weight Decay
MuonW = Muon with Decoupled Weight Decay
AdamH = Adam with Hyperball
MuonH = Muon with Hyperball
- The DNA domain differs from natural language in many ways; a much smaller vocabulary (4 tokens vs ~100k) with near-uniform token frequencies, and local 6–20bp motif grammar that dominates sequence structure, so the observed efficiency gains of Muon in NLP are not guaranteed to transfer.
- We benchmark Muon and Adam variants for regulatory DNA modeling, and show MuonW reaches target validation perplexity with about 37% fewer FLOPs than AdamH.
- For Muon, there is a distinct phase change across the learning rate spectrum: MuonH reaches better validation perplexities at lower learning rates, but at higher rates MuonW starts outperforming MuonH, reaching the best validation perplexity overall.
- For Adam, the stable learning rate window where AdamH outperforms is narrower than for AdamW, but the lowest perplexity is achieved with AdamH.
- We perform a spectral analysis to show how Muon's whitening can promote feature learning by forcing weights away from initialization.
Optimizers dictate the parameter update rules that govern the convergence trajectory of Stochastic Gradient Descent (SGD). At present, variations of Adam1 dominate DNA sequence modeling (e.g., AlphaGenome3, Enformer4, Evo 25). In natural language, Muon2 has been shown to achieve faster convergence, but it is unclear whether this advantage transfers to nucleotide modeling.
The reason is that these domains differ in several fundamental ways. DNA uses a vocabulary of just 4 nucleotides whose token frequencies are far more uniform than the heavy-tailed Zipfian distribution over ~100k tokens in language22. The syntactical rules are explicit and local (transcription factor binding motifs typically span ~6–20bp), and at the short context lengths we study, the signal is dominated by these independent local motif grammars rather than the long-range dependencies that characterize language modeling. In this blog, we explore the behavior of recent optimizers on DNA sequence modeling in regulatory regions, and evaluate whether optimizer choices that work well for LLMs transfer to this distinct setting.
In domains such as coding or mathematics, model outputs can frequently be validated almost instantly. A generated program can be compiled and executed within seconds; a mathematical proof or solution can be checked automatically. This tight feedback loop makes iteration relatively inexpensive, both computationally and financially. However, biology works under a very different set of constraints. When a model proposes a DNA sequence or regulatory element, validating that prediction requires physical experimentation: DNA synthesis, cloning, viral packaging, cell culture, sequencing, and downstream assays. These experiments can take weeks to months and cost thousands to tens of thousands of dollars per iteration.
Because the validation loop is so slow and expensive, significant improvement in training efficiency can have a disproportionately large impact in AI for biology. The capital and resources from every unit of compute saved during model development can instead be redirected toward wet-lab experimentation. Hence, compute efficiency in this domain is not merely an engineering optimization. It directly expands the experimental budget and accelerates the translation of models from in-silico results to real-world biological validation.
Distribution Differences
Zipf’s law in natural language
Nearly all modern optimizer benchmarks are run on natural language data, where token frequencies follow Zipf’s law22, 21: the \(k\)-th most common token appears with frequency \(f(k)\propto 1/k^{\alpha}\) (\(\alpha\approx 1\)). A handful of tokens (“the”, “a”, “is”) dominate, while the vast majority of the ~100k vocabulary is rarely seen.
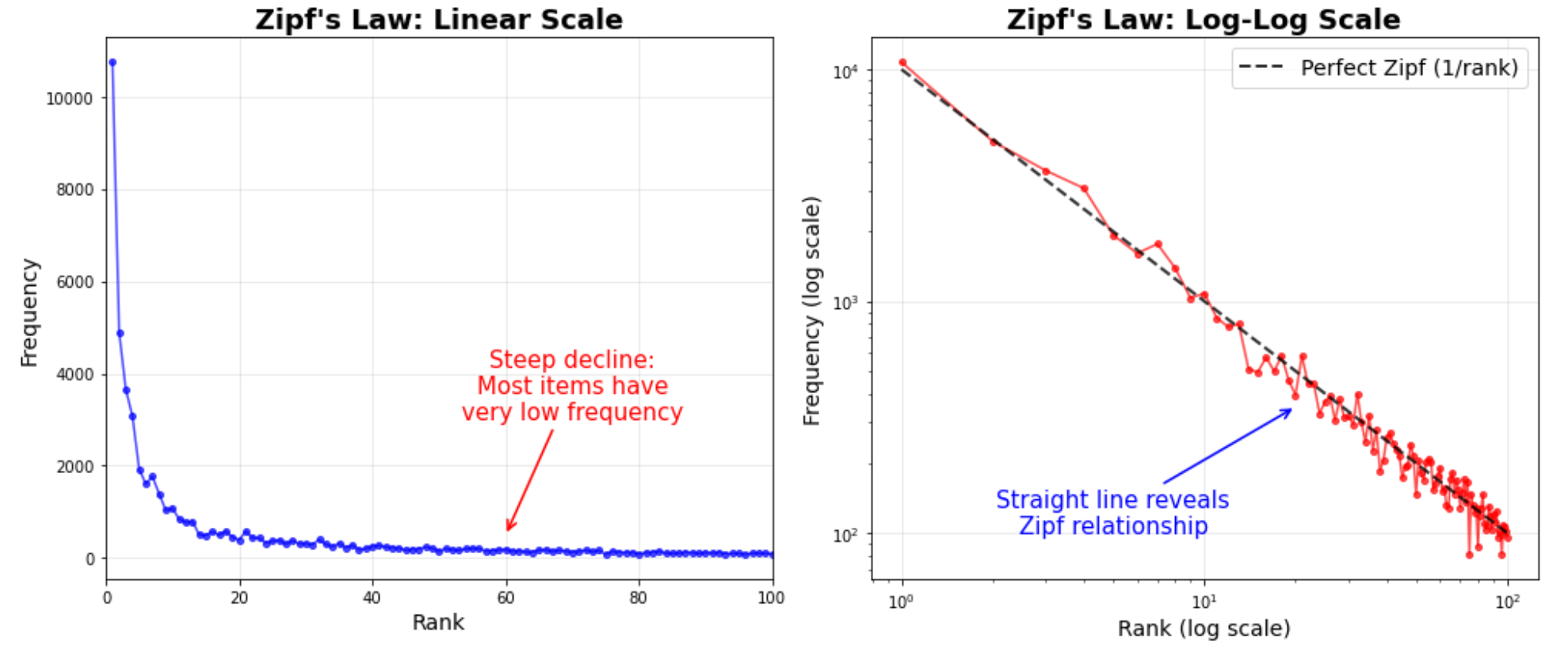
DNA is near-uniform
DNA, by contrast, has a vocabulary of just 4 nucleotides. In our training data (candidate cis-regulatory elements (cCREs) from ENCODE cell lines) the marginal nucleotide frequencies are strikingly close to uniform:
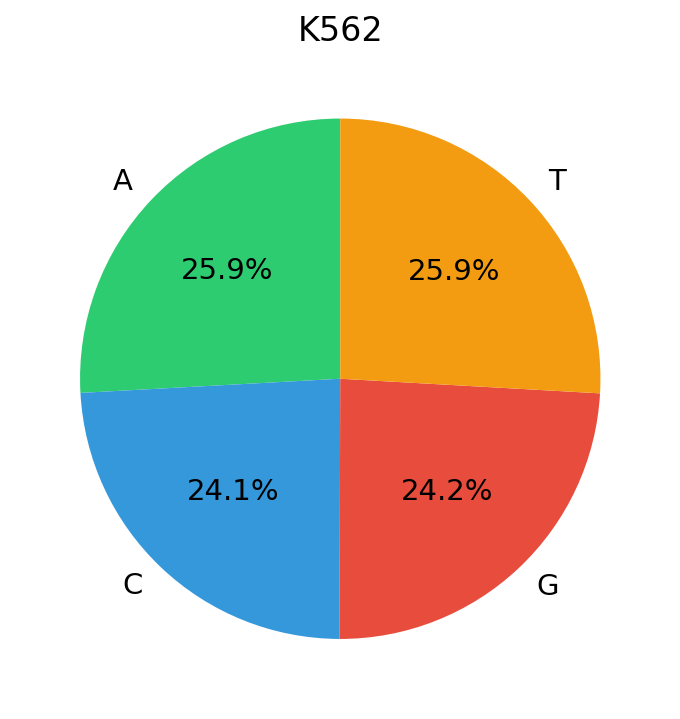
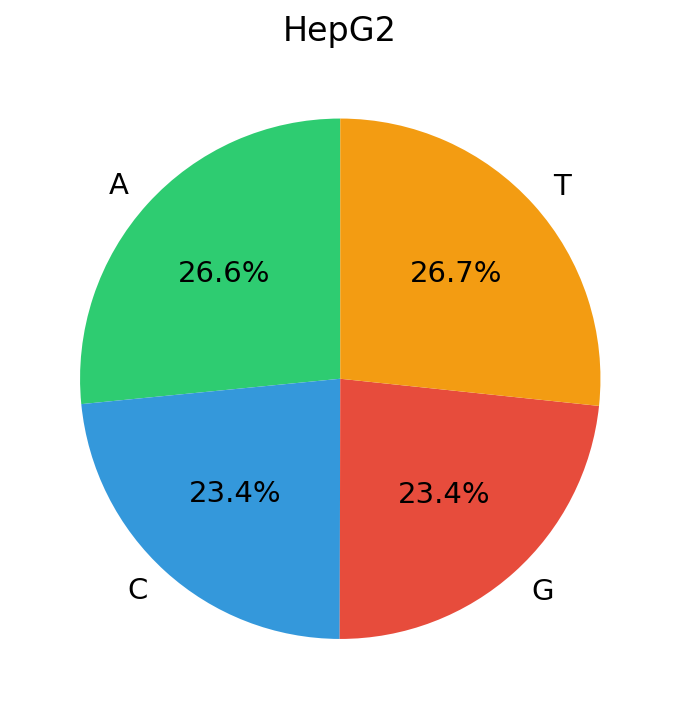
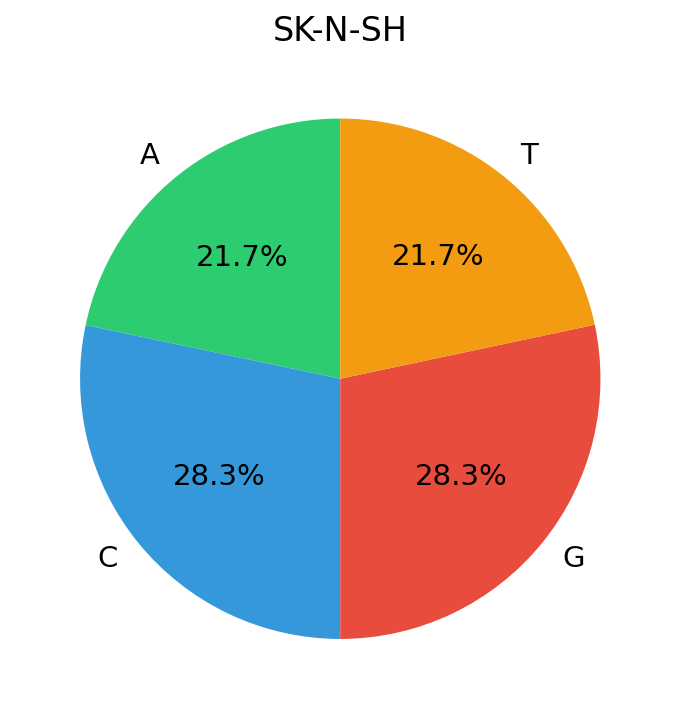
The entropy of DNA’s token distribution sits near its theoretical maximum: \(H_{\text{DNA}}\approx\log_2 4=2\) bits. Natural language, despite its vastly larger vocabulary, has lower normalized entropy because Zipf’s heavy tail concentrates probability mass on a small fraction of tokens. This distinction has concrete consequences for how optimizers see gradients, meaning the gradient statistics across tokens behave very differently numerically.
Why gradient statistics differ: a sketch
Consider a vocabulary of \(K\) tokens with marginal frequencies \(p_1\ge p_2\ge\cdots\ge p_K\). In a mini-batch of \(B\) tokens drawn i.i.d. from \(p\), the expected count of token \(k\) is \(n_k=B\,p_k\). The gradient of the loss decomposes as
\[ g = \frac{1}{B}\sum_{k=1}^{K} n_k\,\bar g_k = \sum_{k=1}^{K} p_k\,\bar g_k, \]where \(\bar g_k\) is the mean gradient contribution conditioned on token \(k\). We can say that Adam’s (see more in Appendix A) running second moment for parameters associated with token \(k\) accumulates as \(v_k\propto p_k\,\mathbb{E}[\|\bar g_k\|^2]+(1-p_k)\,\bar 0=p_k\,\mathbb{E}[\|\bar g_k\|^2]\). The ratio of the largest to smallest second moment therefore scales with the frequency ratio of the most to least common token \( \frac{v_1}{v_K}\;\propto\;\frac{p_1\,\mathbb{E}[\|\bar g_1\|^2]}{p_K\,\mathbb{E}[\|\bar g_K\|^2]} \). If we make the assumption that \(\frac{\mathbb{E}[\|\bar g_1\|^2]} {\mathbb{E}[\|\bar g_K\|^2]}\approx O(1)\) (since all token embeddings and weights are drawn from the same distribution), it can be said that:
\[ \frac{v_1}{v_K}\;\propto\;\frac{p_1}{p_K} \]Zipf (NLP): With \(p_k\propto 1/k\) and \(K\approx 100{,}000\), the dynamic range is \(p_1/p_K\approx K\approx 10^5\). Adam’s per-coordinate \(1/\sqrt{v_k}\) scaling spans orders of magnitude, providing substantial per-direction adaptation that compensates for the wildly uneven gradient contributions of frequent vs. rare tokens.
DNA: With \(K=4\) and \(p_k\approx 1/4\), the dynamic range is \(p_1/p_K\approx 1\). Adam’s adaptive denominator \(\sqrt{v_k}\) is nearly identical across all tokens, reducing the coordinate-wise scaling to an approximately uniform scalar. The per-direction adaptation that makes Adam powerful in NLP provides negligible benefit here, while Muon’s whitened, scale-free updates are naturally suited to this near-isotropic landscape.
Optimizer performance is distribution-dependent
Wilson et al.23 demonstrated empirically that the relative ranking of optimizers changes across domains: adaptive methods (Adam, AdaGrad, RMSProp) find solutions that generalize worse than SGD on image classification tasks, despite converging faster. Yet these same adaptive methods dominate SGD in language modeling, consistent with the classical No Free Lunch theorems24, which prove that no single optimization algorithm is universally superior, and performance is always relative to the structure of the problem.
Our results extend this observation to genomics. The near-uniform token distribution of DNA removes the statistical asymmetry that adaptive methods exploit in NLP, while the low cardinality (\(K=4\)) and positional grammar of regulatory sequences create a loss landscape with fundamentally different curvature. This is precisely why benchmarking optimizers on DNA data directly (as we do here) is essential: rankings established on language corpora do not transfer.
Muon
While Adam1 (see Appendix A) updates can lead to weight stagnation67 and uneven signal propagation, Muon mitigates this by treating layers as matrices and “whitening”, or spreading out updates across singular dimensions to ensure all directions are learned with equal priority. Unlike Adam, which treats weights as flat vectors and risks remaining within the initialization neighborhood (closer to the NTK regime7), Muon forces weights to diverge from their starting points by distributing updates across the matrix space, thereby erasing initial distributions8. This is achieved by constraining all singular values of the weight updates to be close to \(1\), effectively “whitening” the update to distribute the learning signal evenly11.
Just like Adam, we first form a momentum like exponential moving average of gradients, denoted by \(u_t\):
\[ u_t = \beta\,u_{t-1} + (1-\beta)\,g_t, \](with \(u_0=0\)). This plays the same role as Adam's first moment estimate \(m_t\), but is then processed using matrix structure. In our implementation we use Nesterov momentum1Concretely, the input fed into the NS\(_5\) orthogonalization is not the raw gradient \(g_t\) but the lerp \((1-\beta)\,g_t + \beta\,u_{t}\). This Nesterov interpolation means the matrix that NS\(_5\) whitens is already a lookahead blend of the current gradient and the previous momentum buffer, not the gradient at \(W_t\) alone., so the input to the NS\(_5\) normalization is a lookahead lerp between the gradient and the momentum buffer, rather than the gradient at \(W_t\) alone.
We apply the SVD (see Appendix B) to the (momentum) update matrix \(u_t\): \[ u_t = U\Sigma V^\top. \] Muon constructs an update whose singular vectors match those of \(u_t\), but whose singular values are pushed toward \(1\): \[ \tilde u_t = U\,\tilde\Sigma\,V^\top, \] where \(\tilde\Sigma\) is a diagonal matrix with entries close to \(1\) (typically in \([0.7, 1.3]\)), projecting the update toward the Stiefel manifold22The Stiefel manifold is the set of matrices with orthonormal columns (all singular values exactly equal to \(1\)). In practice, finite Newton-Schulz iterations only push singular values toward \(1\), not exactly to it. This is a stricter constraint than the Spectral Sphere, where only \(\sigma_1=1\) is constrained. “whitening” or “equalizing” the update across singular dimensions.
Intuitively, this prevents a few directions from dominating the step, and encourages motion in many independent directions of the layer's matrix space. In contrast to optimizers that treat parameters as a flat vector, Muon explicitly uses matrix structure, which can help avoid updates that remain concentrated near the initialization subspace.
In practice, the resulting parameter update has the form \[ W_{t+1} = W_t + U_t, \qquad U_t = -\eta\,\tilde u_t, \] (with optional weight decay applied as described in Appendix A).
Connecting Muon to norm control
Muon already manipulates singular values of the update (by pushing those of \(\tilde u_t\) toward \(1\)), which suggests a different view of regularization than standard weight decay. Classical weight decay controls the \(\ell_2\) or Frobenius norm of the weight matrices (defined as \(\|W\|_F =\|\vec W\|_2= \sqrt{\sum_{i}\sum_jw_{ij}^2}\)3\(\vec W\) denotes the vectorized form of matrix \(W\); more specifically, if \(W=[c_1, c_2, \dots, c_n]\) where \(c_i\) is the \(i\)th column of \(W\), then \(\vec W=\begin{bmatrix} c_1\\c_2\\\vdots\\c_n \end{bmatrix}\) has them merged into one column.4It also happens to be the case that \(\|W\|_F=\sqrt{\sum_i \sigma_i^2}\), but this is a bit of a digression and we will not prove this here.), but in a matrix aware setting one can instead target properties tied to singular values:
- Rank / intrinsic dimension: shaping the smaller singular values can encourage using many subspaces of the hidden stream, rather than collapsing the layer to an effectively low rank map.
- Stability: bounding the largest singular value (the spectral norm) controls the layer Lipschitz constant, and helps prevent activation and gradient blowups12, 115Concretely, if all singular values of the update equal \(1\), then \(\tilde u_t\) is orthogonal and \(\|\tilde u_t\, x\| = \|x\|\) for every input \(x\) (provided \(\tilde u_t\) is square). More generally, \(\|\tilde u_t\, x\| \leq \sigma_1(\tilde u_t)\,\|x\|\), so pushing \(\sigma_1\) toward \(1\) directly caps the maximum activation amplification per layer..
This perspective is especially relevant for high dimensional, structured sequence representations like DNA. The combinatorial grammar of regulatory motifs demands that many spectral dimensions remain active; a low rank collapse in the update would erase the subtle, distributed signals that distinguish functional sequences from background.
Weight Regularization
Why is weight decay necessary?
Without weight decay, the norm of the weight matrices grows \(\propto \sqrt{t}\) as training progresses10. This unchecked growth inflates the parameter scale relative to the step size, effectively shrinking the learning signal and hindering convergence17. Weight decay counteracts this by imposing an \(\ell_2\) bias that drives the norm toward an equilibrium value9110, and empirically, adding decay improves both Adam and Muon1019. The reason is a clean separation of concerns: the optimizer determines directional update structure (moments for Adam, singular direction shaping for Muon), while decay provides a control knob on overall parameter scale9.
Although weight decay drives the norm toward an equilibrium, the weights only “hover” near it, and the optimizer must still search the space created by these fluctuations. Even if the norm ‘hovers’ within just \(0\lt\varepsilon\ll N\) of the equilibrium \(N\) (or in the range \([N-\varepsilon, N+\varepsilon]\)), we still have to consider a relatively large space of values within the hyperball. By Appendix C, nearly all of this volume lies in a thin shell at the boundary.
Crucially, with correctly placed RMSNorms, these matrices become scale invariant (Appendix F); their scale does not impact capacity, only direction. Since scale is irrelevant, wouldn't it be more efficient to fix the norm (set \(\varepsilon=0\)) and let the update focus solely on direction?
The Hyperball update
The intuition of Hyperball10 is to, for a weight matrix \(W\), simply fix the Frobenius norm of \(W\) to the initial radius \(R := \|W_0\|_F\), and the norm of update \(U\) to \(\eta R\). Rather confusingly, this confines the weight matrix to a hypersphere of radius \(R\), not a ball6Note that a hypersphere and hyperball are not the same thing. A ‘ball’ refers to the entire solid object, but a ‘sphere’ refers only to the shell/boundary of said ball., but let us ignore this superficial detail. Suppose \(\mathrm{Normalize}(A):=A/\|{A}\|_F\). Given an optimizer’s proposed update step \(\tilde u_t\), let the actual update be: \[ U_t = -\eta R\,\mathrm{Normalize}(\tilde u_t), \] then let \[ W_{t+1} = R\,\mathrm{Normalize}(W_t + U_t). \] What makes this optimization special is that it can be wrapped around any optimizer update, so it works with Adam and Muon (using it alongside weight decay would be useless, as we hard-set the weight norms in the wrapper function).
Note that not only do we set the weight norm to be \(R\), but the update vector norm is set to \(\eta R\). Let \(\Delta W = W_{t+1}-W_t\), if we make the generous assumption that \(\|\Delta W\|_F = O(\|U_t\|_F)\), we can see that we have a relative step size of: \[ \frac{\|\Delta W\|_F}{\|W_t\|_F}=\frac{O(\|U_t\|_F)}{\|W_t\|_F}=O(\eta) \] which is an easily adjustable hyperparameter.
Now, this is a generous assumption, so we can make better estimates. Let us use the Frobenius norm throughout the next calculation; suppose that we know the expected normalized dot product7The Frobenius inner product \(\langle A, B\rangle_F=\operatorname{Tr}(A^TB)=\langle\vec A,\vec B\rangle=\sum_{i,j}a_{ij}b_{ij}\) is the sum of the element wise product of the matrices \(A\) and \(B\). \(\gamma=\frac{\langle W_t, U_t\rangle_F }{\|U_t\|_F\|W_t\|_F}=\frac{\langle W_t, U_t\rangle_F}{\eta R^2}=\cos\theta\), where \(\theta:=\angle(\vec W_t, \vec U_t)\). By applying the cosine and sine rules to the triangle formed by the origin, \(W_t\), and \(W_t+U_t\) (see the interactive visualization below and Appendix D for the full derivation), we obtain the exact step size:
\[ x := \|\Delta W\| = R\sqrt{2}\sqrt{1 - \cos\phi}, \quad\text{where}\quad \cos\phi = \sqrt{1-\frac{\eta^2(1-\gamma^2)}{1+\eta^2+2\eta\gamma}}. \]When \(\gamma,\eta\in(0,1)\), a careful bounding argument (Appendix E) shows that the relative step size lies in \(\frac{x}{\|W_t\|}\in (0,\sqrt{2-\sqrt{2}})\approx (0, 0.765)\). This is quite loose without knowing \(\gamma\); as an example, for practical learning rates \(\eta\in(10^{-4},10^{-1})\) with an ideal \(\gamma=0\), the bound tightens to roughly \((0.0001, 0.0996)\).
Estimations for low \(\eta\)
Knowing that our practical learning rates are such that \(\eta^2\ll1\) and \(\gamma\eta\ll 1\), we can make some estimations, like \(1+\eta^2+2\eta\gamma\approx1\), so we get \(x\approx R\sqrt{2}\sqrt{1-\sqrt{1-(\eta^2-\gamma^2\eta^2)}}\). Using \(\sqrt{1-z}\approx 1-z/2\) we can see \(x\approx R\sqrt2\sqrt{1-(1-(\eta^2-\gamma^2\eta^2)/2)}=R\eta\sqrt{1-\gamma^2}=R\eta\sin\theta\), which is just a tangent space approximation of the step size! This would make the relative step size \(\frac{x}{\|W_t\|}\approx\eta\sqrt{1-\gamma^2}\), and we get something very similar to our initial estimate of \(O(\eta)\). In fact, for \(\gamma=0\), we get \(\frac{x}{\|W_t\|}\approx \eta\)!
It is very ‘nice’ that \(\frac{x}{\|W_t\|}\propto\eta\), because when we have a weight decay instead, the effective step size is a nonlinear function of \(\eta\) and \(\lambda\)10, which adds another layer of complexity to the solution space.
Results
To isolate the effect of the optimizer, we hold model architecture, dataset, training duration, and all non-optimizer hyperparameters constant across runs, varying only the optimizer and learning rate. We track validation perplexity throughout training as a highly interpretable and sensitive measure of model capacity8The model is a multifunctional architecture similar to Axis, trained on a set of candidate cis-regulatory elements (cCREs) from the ENCODE v4 registry that are cell-type-specific to one of three cell lines: K562, HepG2, and SK-N-SH. Training was limited to 20 epochs due to compute constraints; the loss has not begun to saturate (we have trained to much lower cross-entropy in prior runs), so these results reflect relative optimizer comparisons, not absolute model quality.. We use perplexity as a sensitive proxy for sequence modeling quality; in practice we expect improvements to correlate with better motif and grammar modeling, and we plan to validate this directly with motif-centric downstream tasks. By evaluating against a held-out validation split, we extract a clear empirical picture of optimizer performance across varying learning rates and training checkpoints (saved every epoch).
Final test perplexity by learning rate
The line plots below illustrate the final validation perplexity (at the last checkpoint) for each optimizer pair as a function of the learning rate (log scale). Lower perplexity indicates superior probability mass placement on the target sequence.
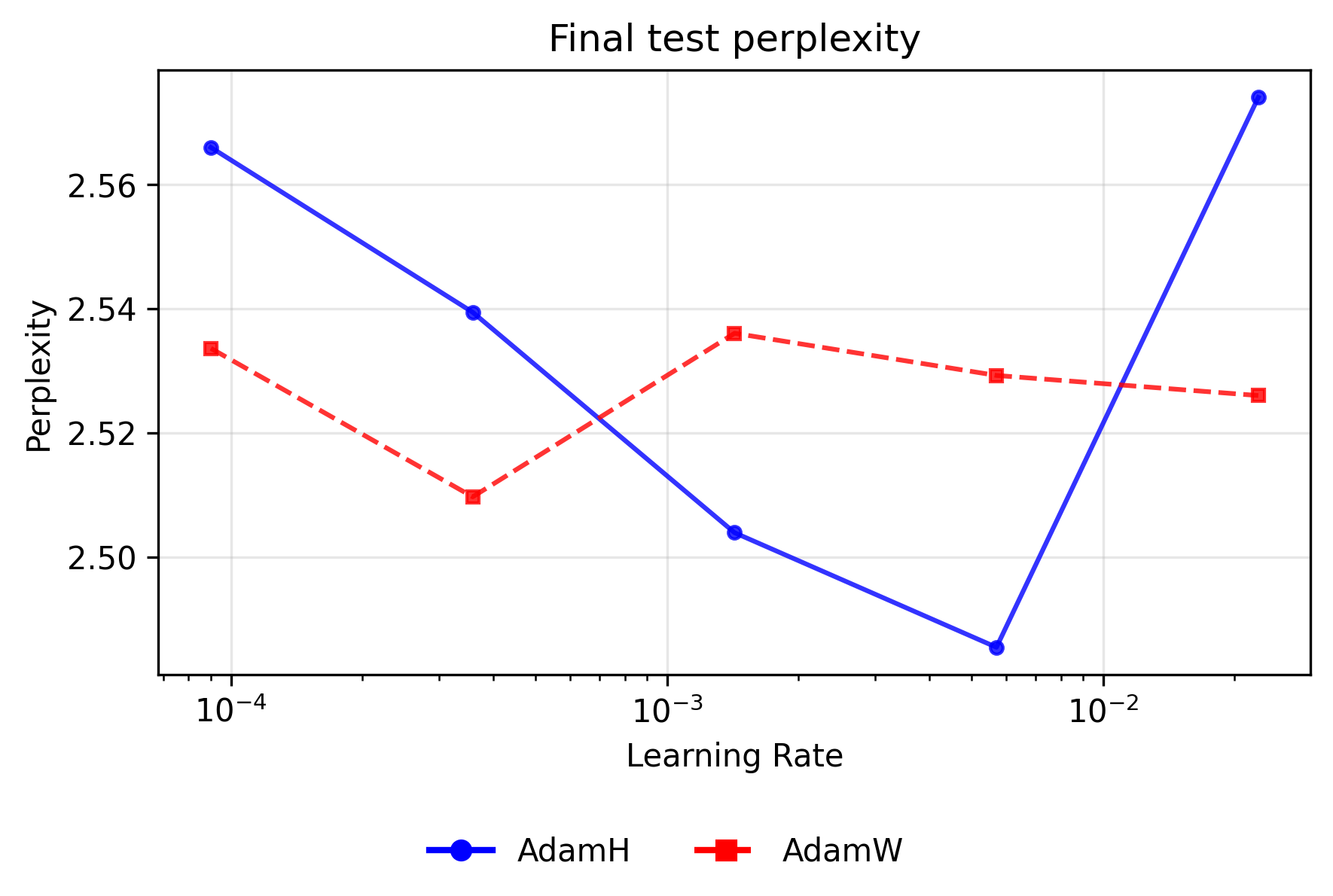
For Adam variants, applying the Hyperball constraint improves peak performance but sharply narrows the stable operating window. AdamH achieves the absolute lowest overall perplexity for the Adam family (∼2.485) at a moderate learning rate of ∼\(5.69 \times 10^{-3}\). However, AdamW proves dramatically more resilient at the extremes. At the lowest learning rate (∼\(9.00 \times 10^{-5}\)), AdamW's independent weight decay slowly regularizes the network without disrupting the coordinate-wise updates, maintaining a lead (∼2.534 vs. ∼2.566). Conversely, at the highest rate (∼\(2.27 \times 10^{-2}\)), AdamH degrades sharply (∼2.574); its rigidly fixed norm overrides the natural decay in step size that occurs when weights grow, causing the optimizer to catastrophically bounce around the local minimum, while AdamW remains relatively stable (∼2.526).
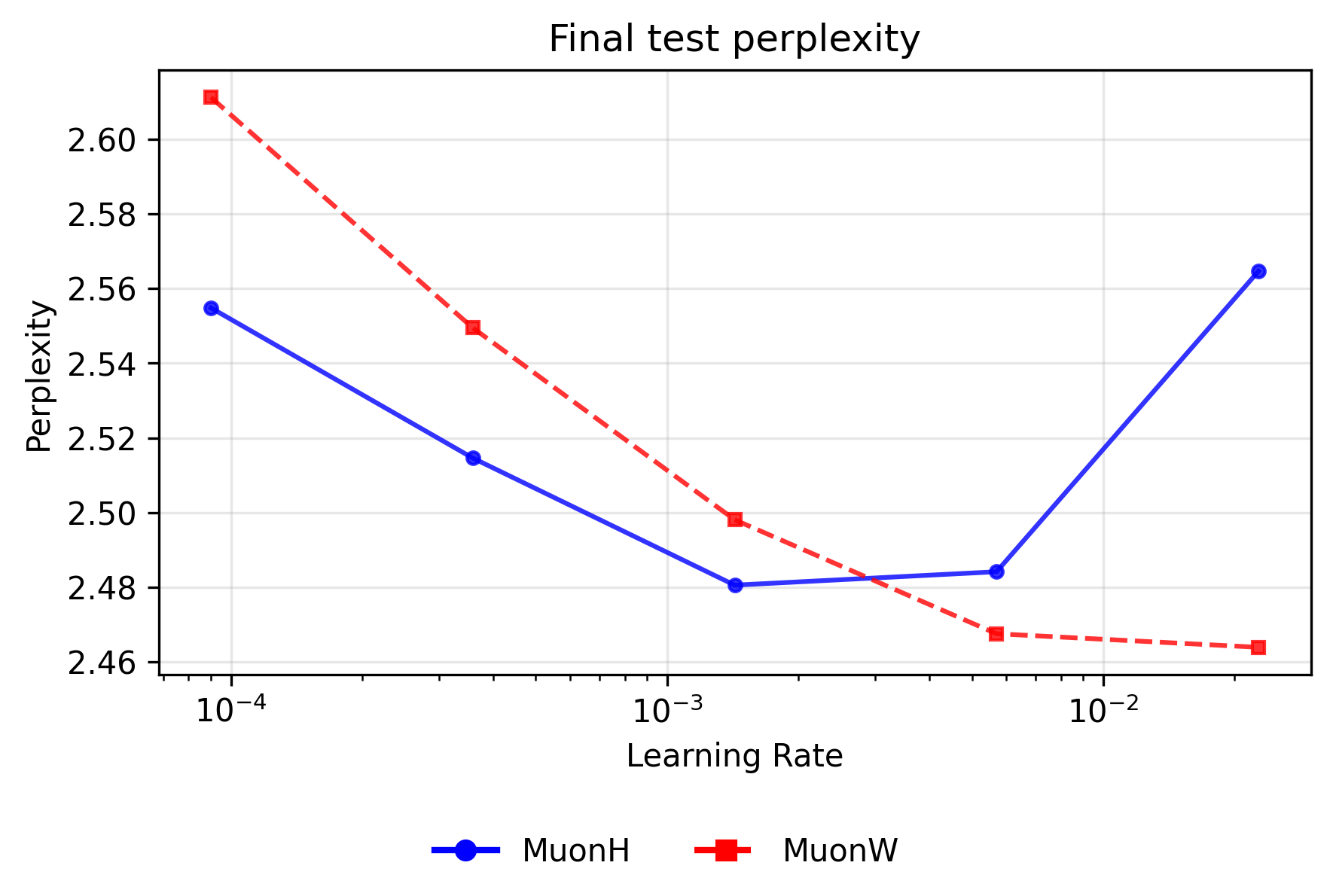
The dynamics for the Muon optimizers are perfectly inverted: Hyperball dominates at lower learning rates, whereas independent weight decay scales flawlessly to the highest rates. Because Muon's whitened updates are entirely scale-free, MuonW relies on the unbounded growth of the weight norm to act as an implicit learning rate scheduler (decreasing the relative step size over time). At higher learning rates (∼\(2.27 \times 10^{-2}\)), this rapid norm growth naturally cools the optimization, allowing MuonW to comfortably digest large initial steps and achieve the absolute best validation perplexity across all sweeps (∼2.464). MuonH’s fixed norm eliminates this vital annealing phase, permanently trapping it in a high-temperature regime and causing perplexity to rise (∼2.565). Conversely, at small learning rates like ∼\(9.00 \times 10^{-5}\), where preventing further step-size decay is actually beneficial, MuonH easily outperforms MuonW.
Overall findings
These validation results, together with the training loss curves below, paint a consistent picture: the Hyperball constraint does not uniformly improve both optimizers, and the best overall configuration is Muon with independent weight decay (MuonW)9The Hyperball blog10 actually shows that for Muon, the losses are comparable for models with ≤ 500M parameters, and Hyperball dominates for the largest model of >1B parameters. Our largest model is actually ~420M parameters large (as we are somewhat compute bound), so it is still possible for MuonH to outperform MuonW at a larger scale..
Why does Hyperball worsen Muon?
We hypothesize that this is because Hyperball’s re-projection scales all singular values of the weight matrix by the same multiplicative factor. When Hyperball maps \(W_{t+1} = R\,(W_t + U_t)/\|W_t + U_t\|_F\), it shrinks every singular direction of \(W\) equally10It is actually possible to be on both the Frobenius and Spectral sphere at once as they DO intersect, but our algorithm does not guarantee that we enter the intersection. As a clarification: There exists an inequality \(\|W\|_2\le \|W\|_F\le \sqrt{\min(m, n)}\|W\|_2\), so one might believe that \(\|W\|_F\in[1,\sqrt{\min(m, n)}]\) guarantees that \(W\) lies in the intersection, but this is a necessary condition, not a sufficient one (think of a rank 1 matrix within this range)!. The dominant singular values of \(W\), being large, survive this downscaling, and they remain the dominant share of the fixed energy budget \(\|W\|_F^2 = \sum_i \sigma_i^2 = R^2\). The smaller singular values of \(W\), however, cannot: Muon’s whitening of the update matrix tries to grow them step after step by distributing the learning signal equally across all singular directions, but the uniform rescaling of the weight matrix pulls them back down proportionally each time. Because they never accumulate enough energy to matter, the small directions effectively die while the large ones persist, concentrating the spectrum into fewer and fewer dominant modes. The spectral metrics below support this: MuonH’s spectral entropy and participation ratio collapse over training, consistent with the small singular directions being progressively eroded by the uniform rescaling.
Adam under the same Hyperball constraint does not suffer this fate, because without whitening the spectrum is already concentrated in the task-relevant directions; the uniform rescaling therefore does comparatively little damage. Weight decay, on the other hand, does not alter the Muon update at all, it only decays the matrix the update is added to, so the whitening and the regularizer rarely conflict.
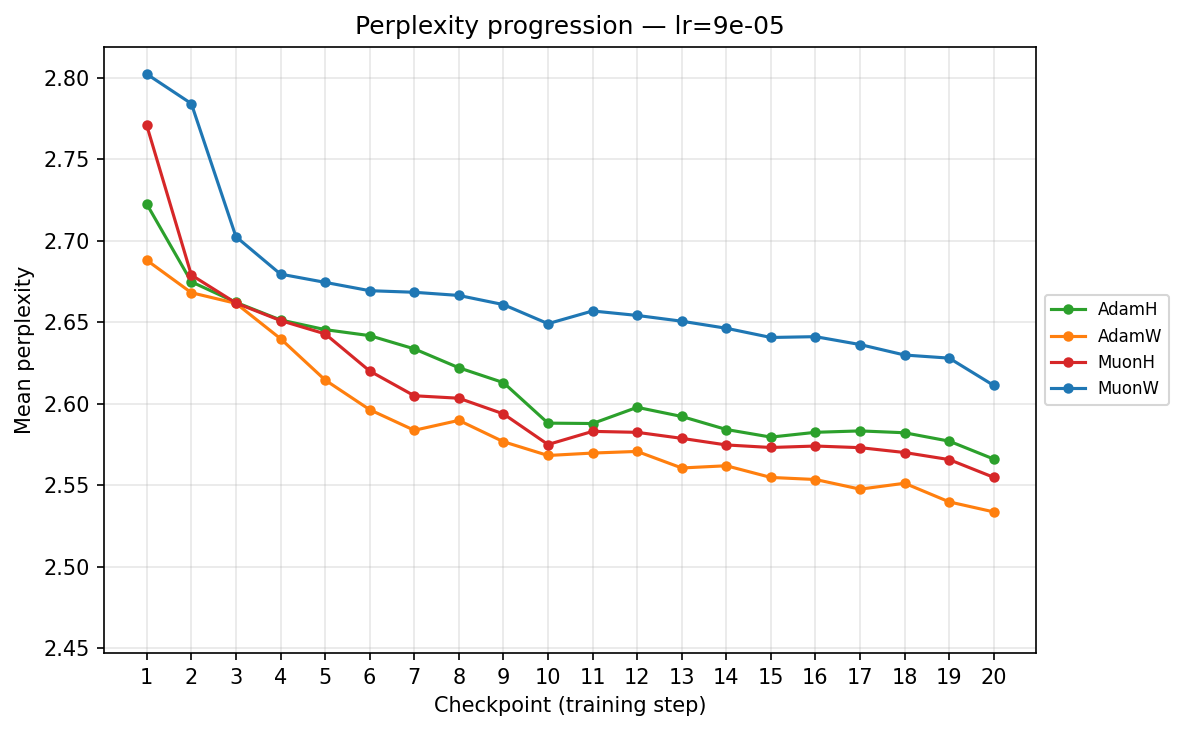
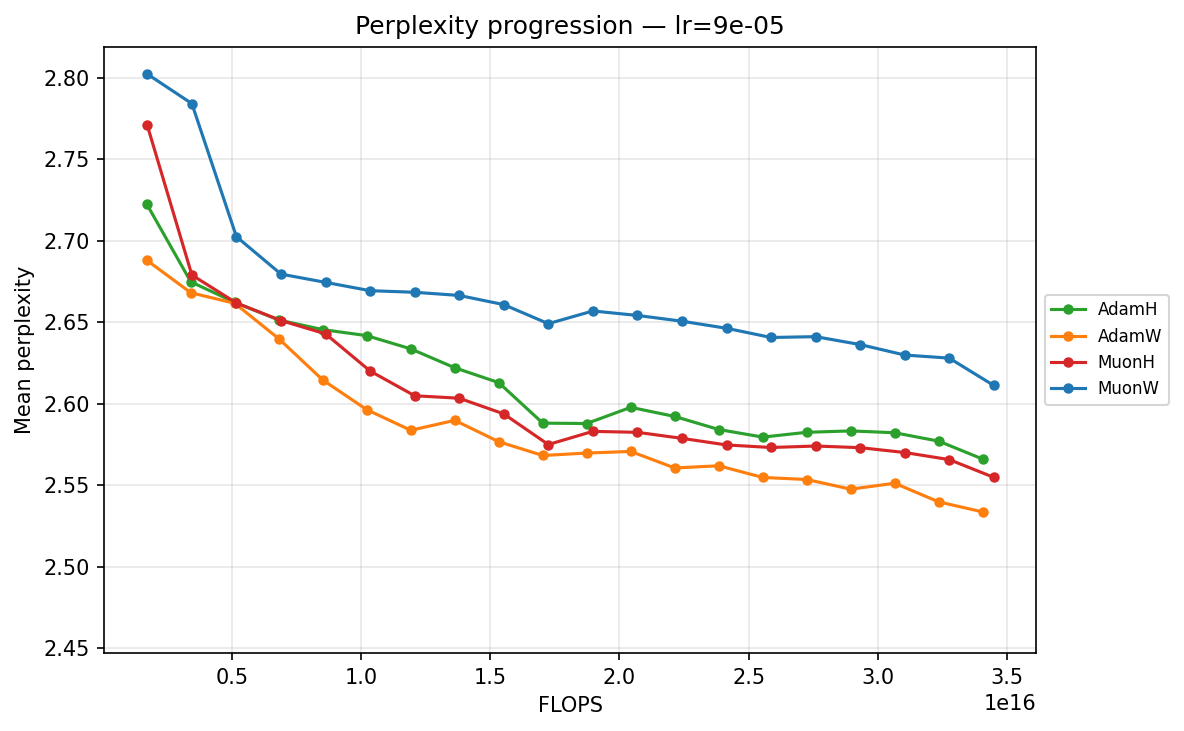
Perplexity progression by checkpoint and FLOPS
To understand the temporal dynamics behind the final results, we track the mean validation perplexity over the 20 checkpoints. Because validation perplexity can be volatile, observing its trajectory provides crucial context about optimizer stability and the risk of overfitting. We present each progression in two views: by training step (checkpoint) and by total FLOPS. The FLOPS axis accounts for the per-step compute cost of each optimizer, including forward/backward passes and the optimizer update itself (e.g. Muon's SVD is more expensive per step than Adam's elementwise update). We can view this progression from two perspectives: comparing optimizers at each learning rate, and comparing learning rates for each optimizer.
First, we slice the data by learning rate, placing all four optimizers head-to-head at each scale:
By checkpoint
By FLOPS
lr ≈ 9.00×10⁻⁵
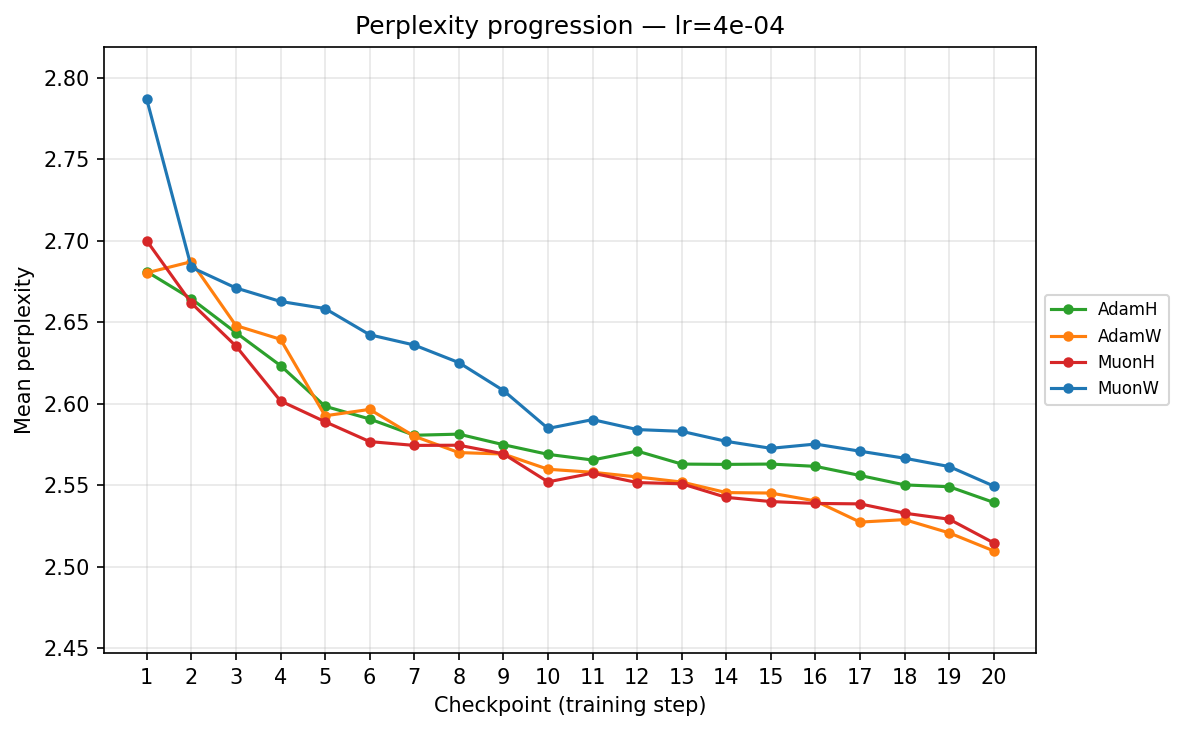
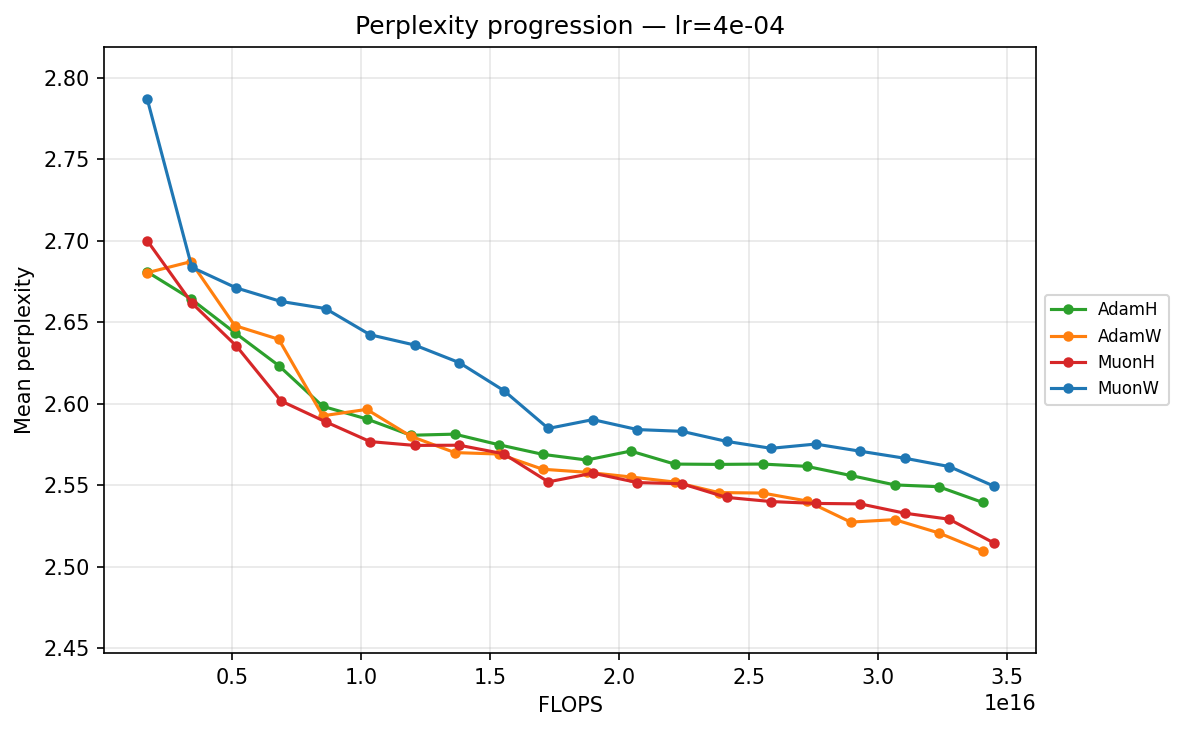
lr ≈ 3.59×10⁻⁴
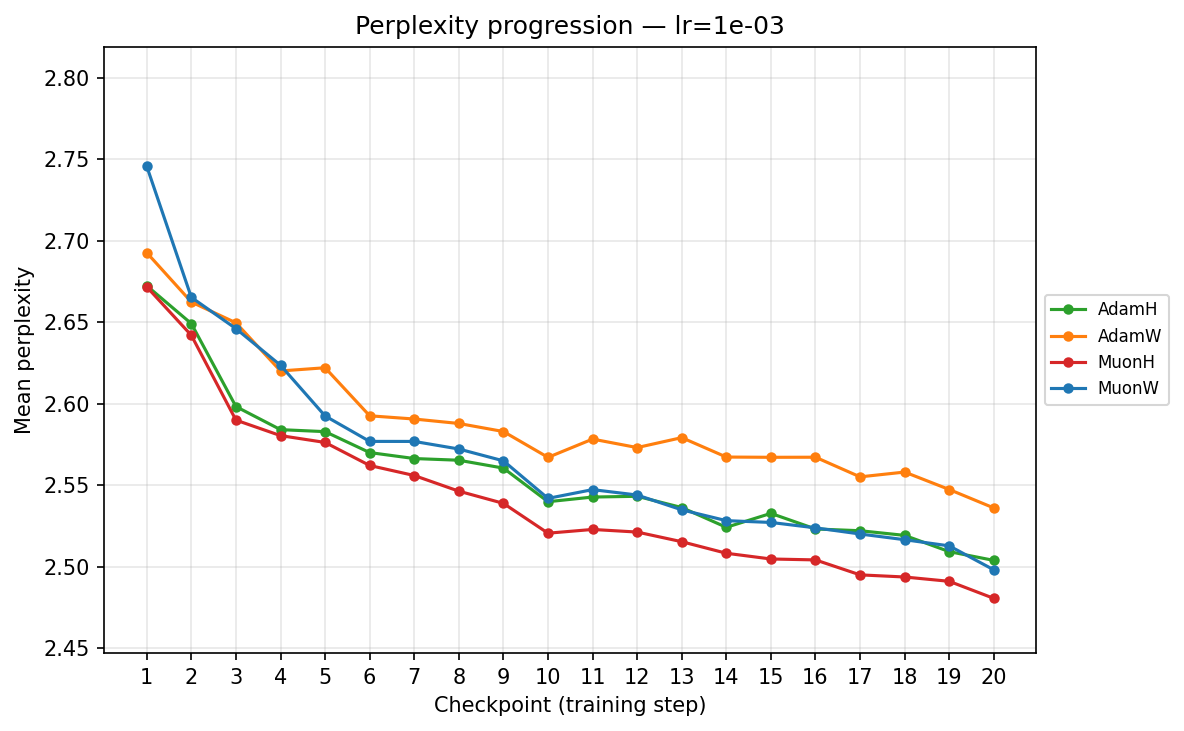
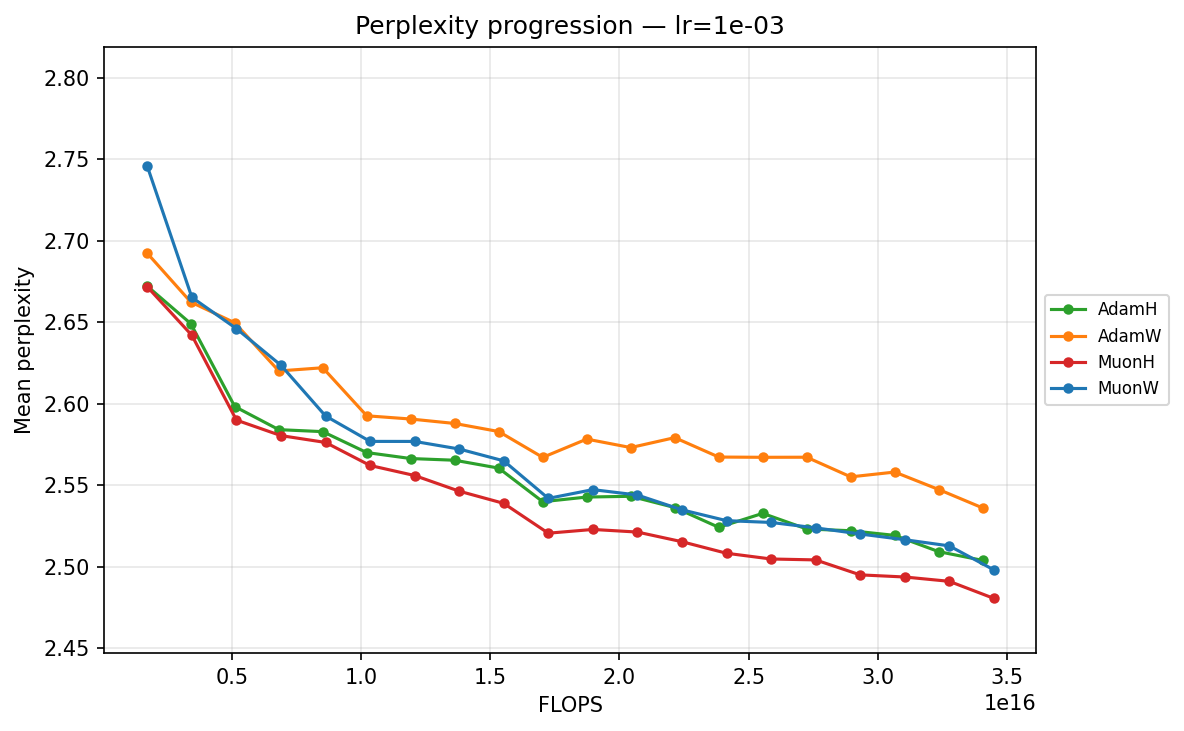
lr ≈ 1.43×10⁻³
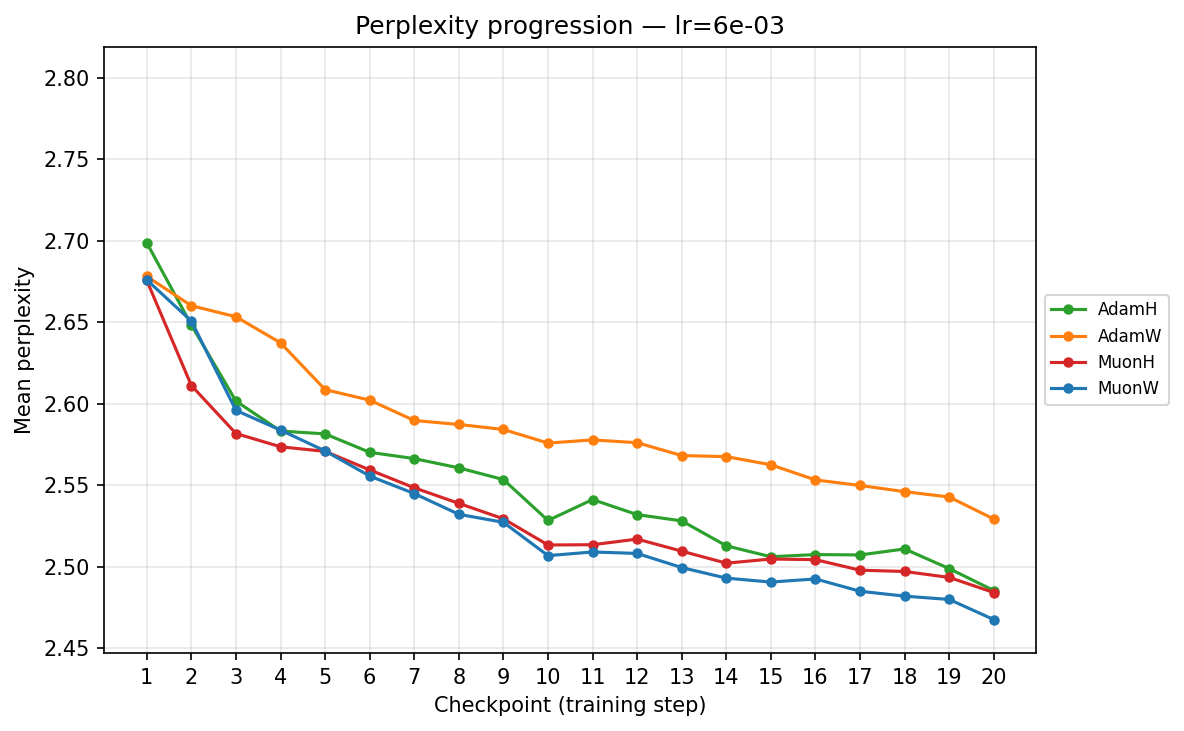
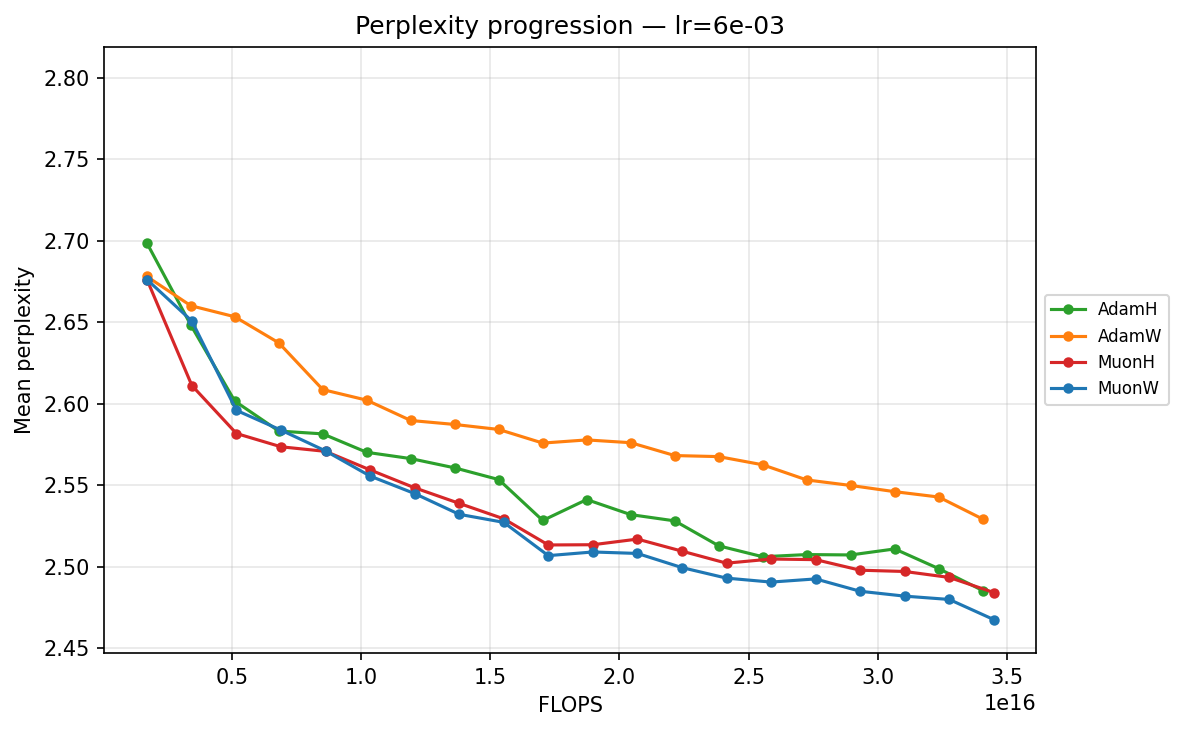
lr ≈ 5.69×10⁻³
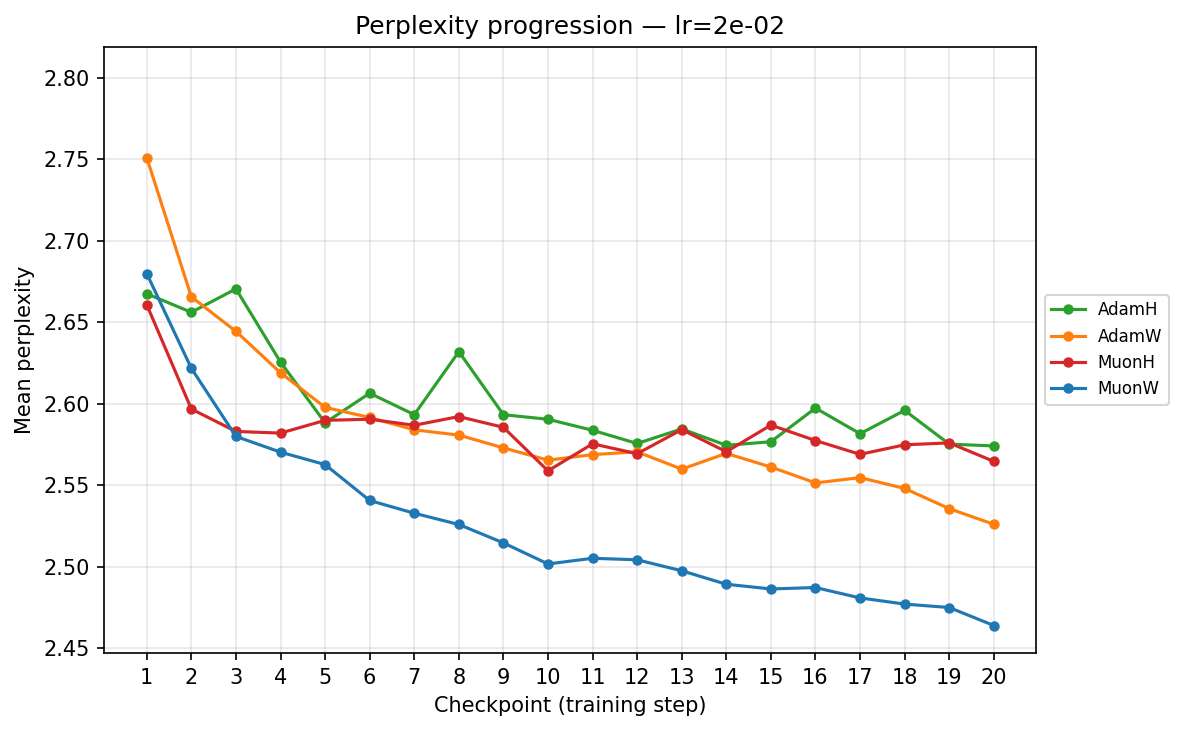
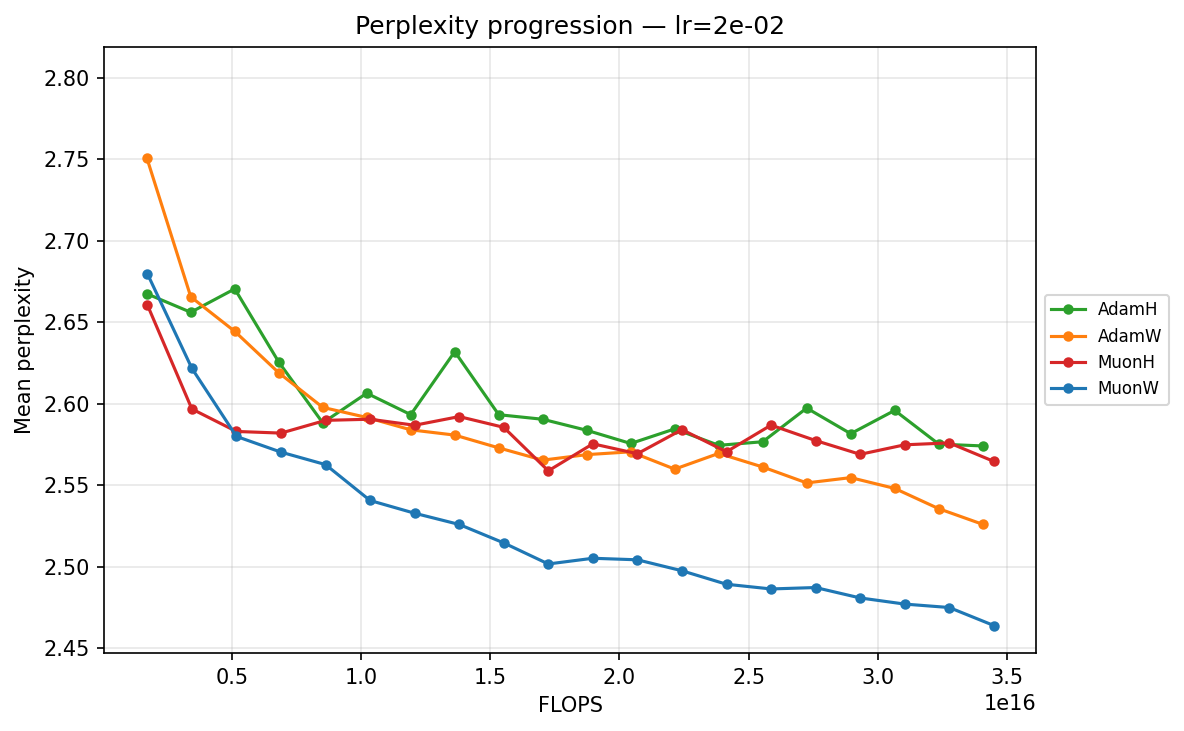
lr ≈ 2.27×10⁻²
Analyzing these cross-sections reveals a clear shifting of the guard as the step size scales up:
- Low Learning Rates (∼\(9.00 \times 10^{-5}\) to ∼\(3.59 \times 10^{-4}\)): Training is slow but highly stable. Here, the strict norm constraints of Hyperball provide a massive early acceleration. MuonH drops aggressively in the first few epochs, cleanly outperforming MuonW, which converges much more deliberately. AdamH, strangely, struggles at the absolute lowest rate compared to AdamW, but tightens the gap as the LR increases.
- Mid-Range (∼\(1.43 \times 10^{-3}\) to ∼\(5.69 \times 10^{-3}\)): We enter the optimal operating window for most models. At ∼\(5.69 \times 10^{-3}\), AdamH finally hits its stride, overtaking AdamW to reach the lowest perplexity in the Adam family. Concurrently, MuonW overtakes MuonH. MuonW leverages the larger step size perfectly, free from the norm bound that begins to bottleneck MuonH's performance.
- High Learning Rate (∼\(2.27 \times 10^{-2}\)): We observe sharp destabilization for fixed-norm constraints (AdamH, MuonH); their trajectories bounce erratically and plateau at suboptimal levels, likely due to how hard constraints interact with high-variance updates. In stark contrast, MuonW thrives, plunging rapidly to achieve the absolute lowest validation perplexity (∼2.464) across all runs. AdamW remains remarkably resilient but reaches higher validation perplexity than MuonW, suggesting that MuonW achieves higher effective capacity in this regime.
Next, we transpose the axes to view the same data grouped by optimizer, illustrating their individual hyperparameter sensitivities:
By checkpoint
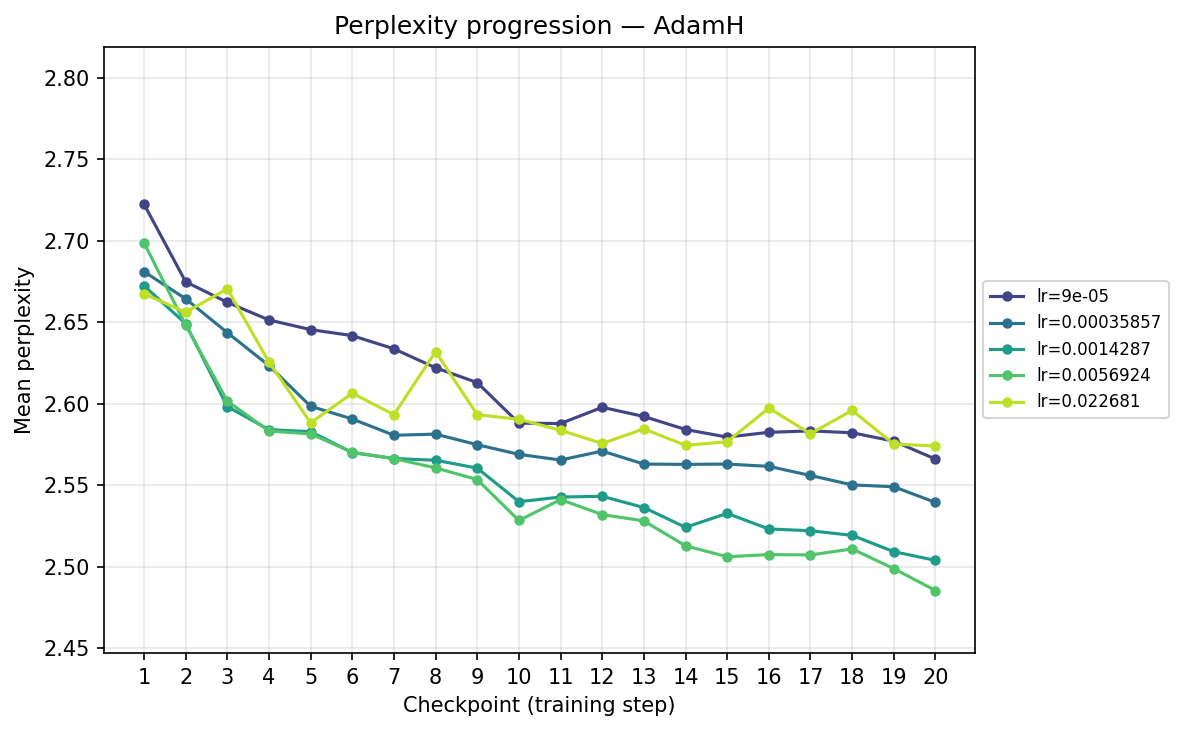
By FLOPS
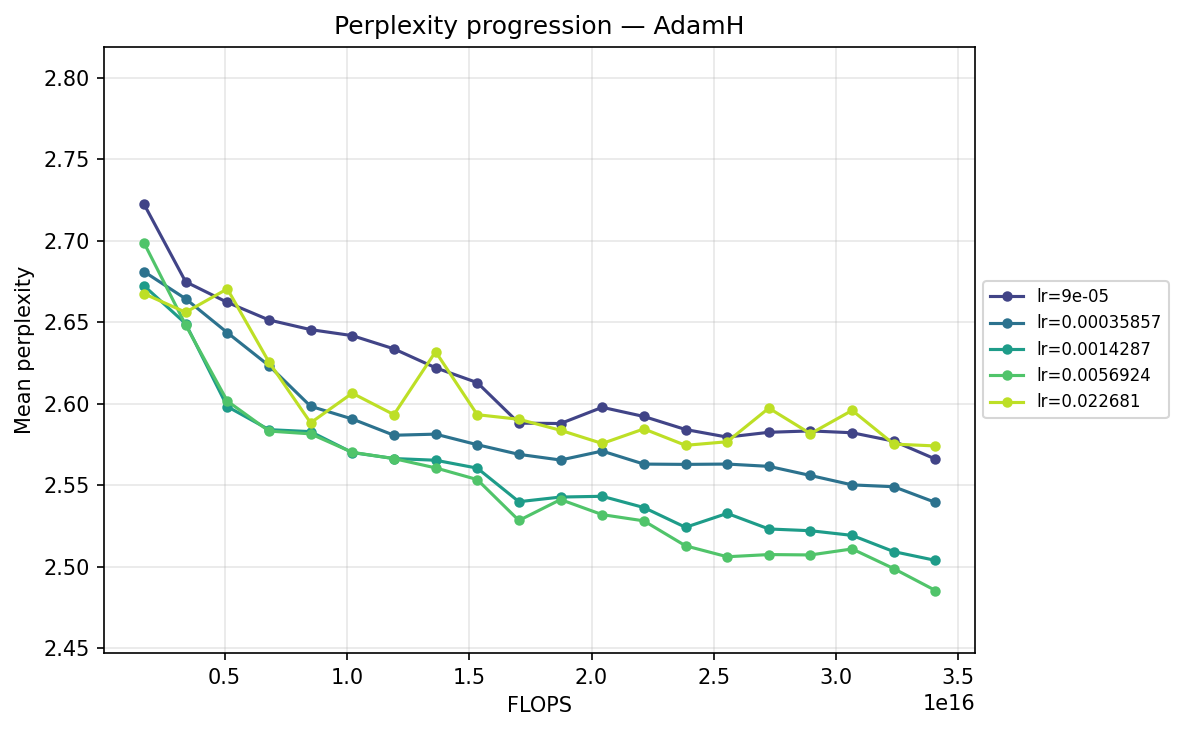
AdamH
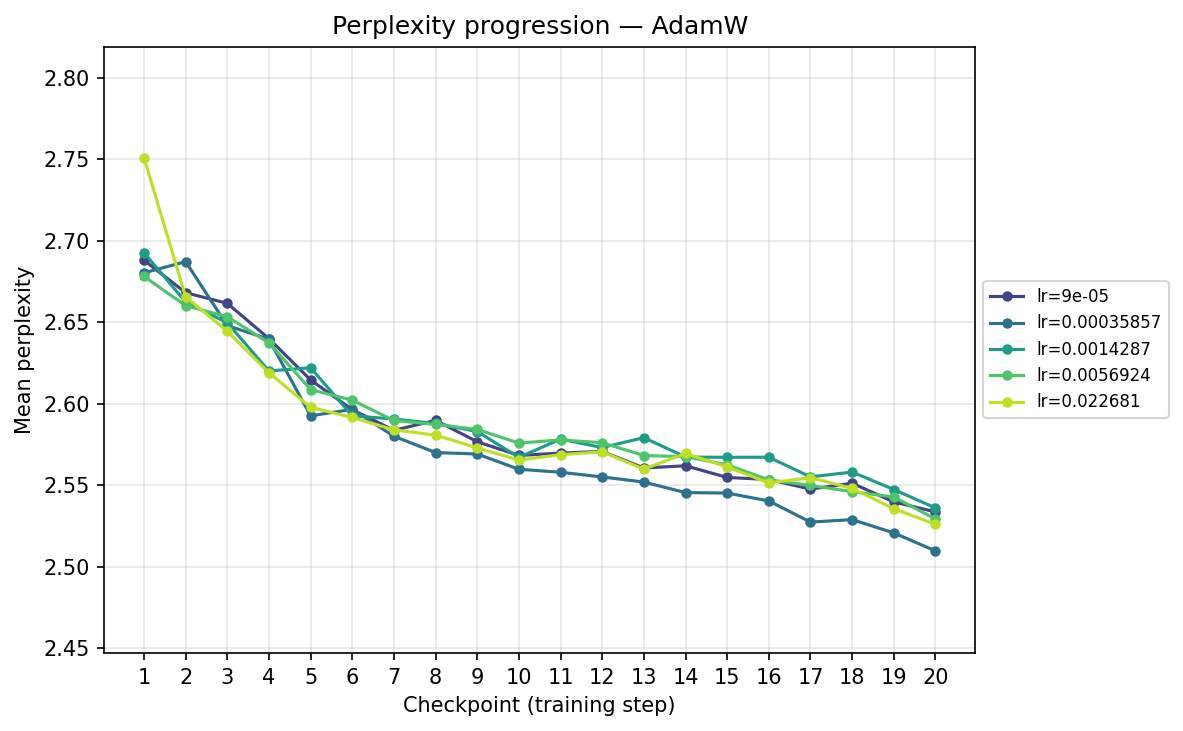
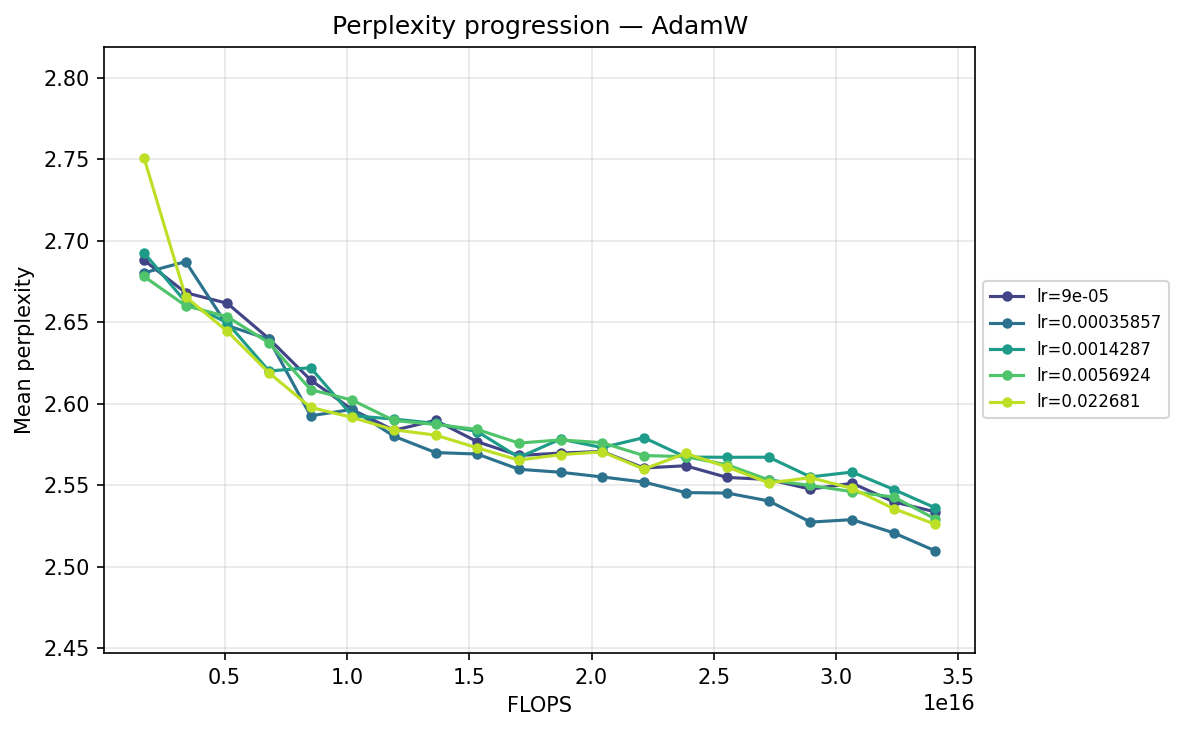
AdamW
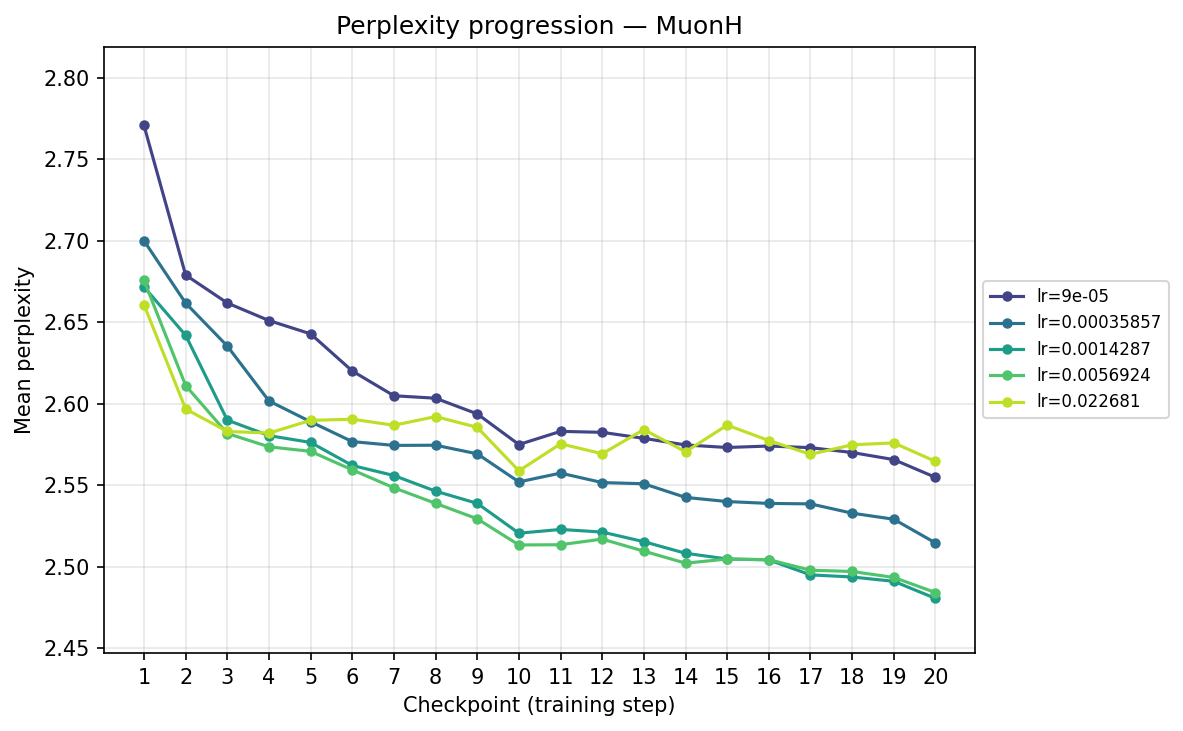
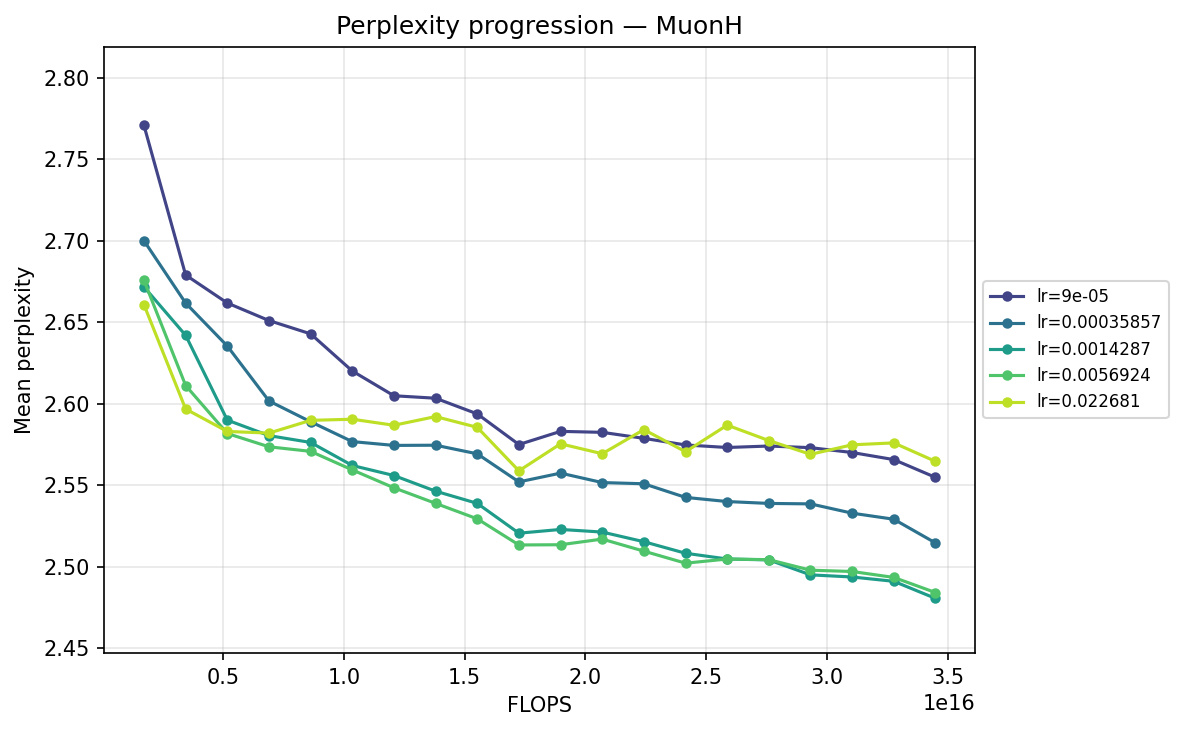
MuonH
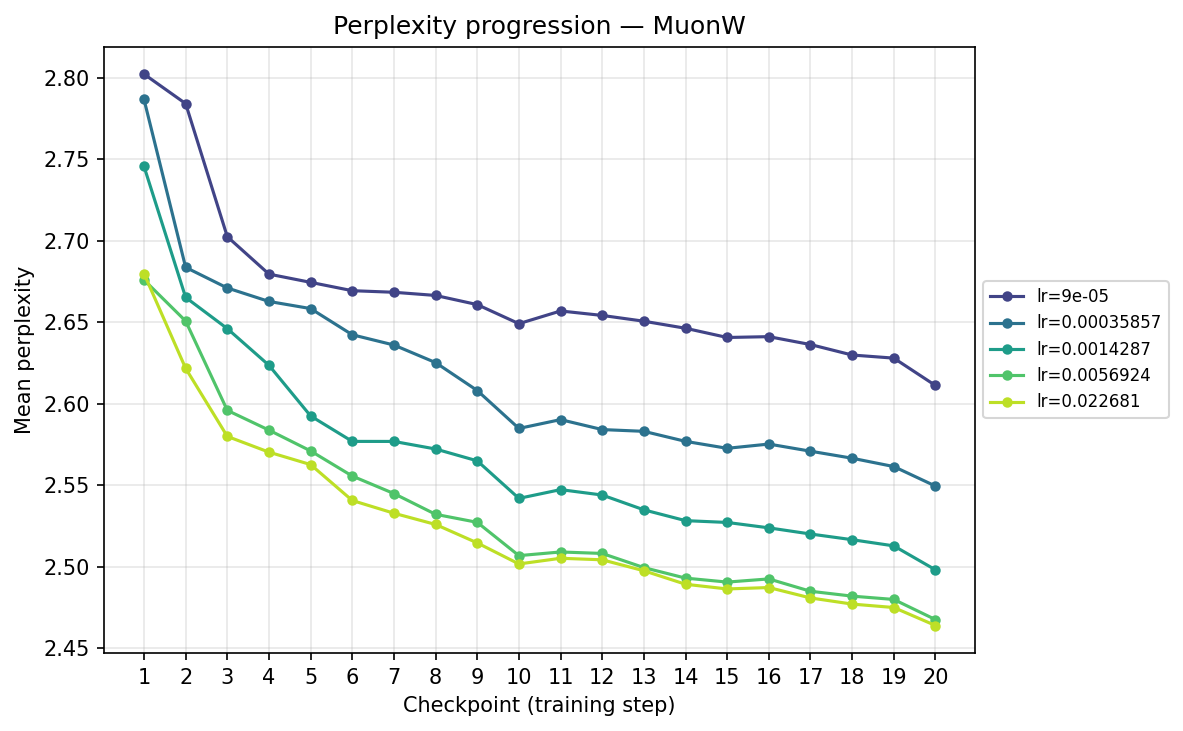
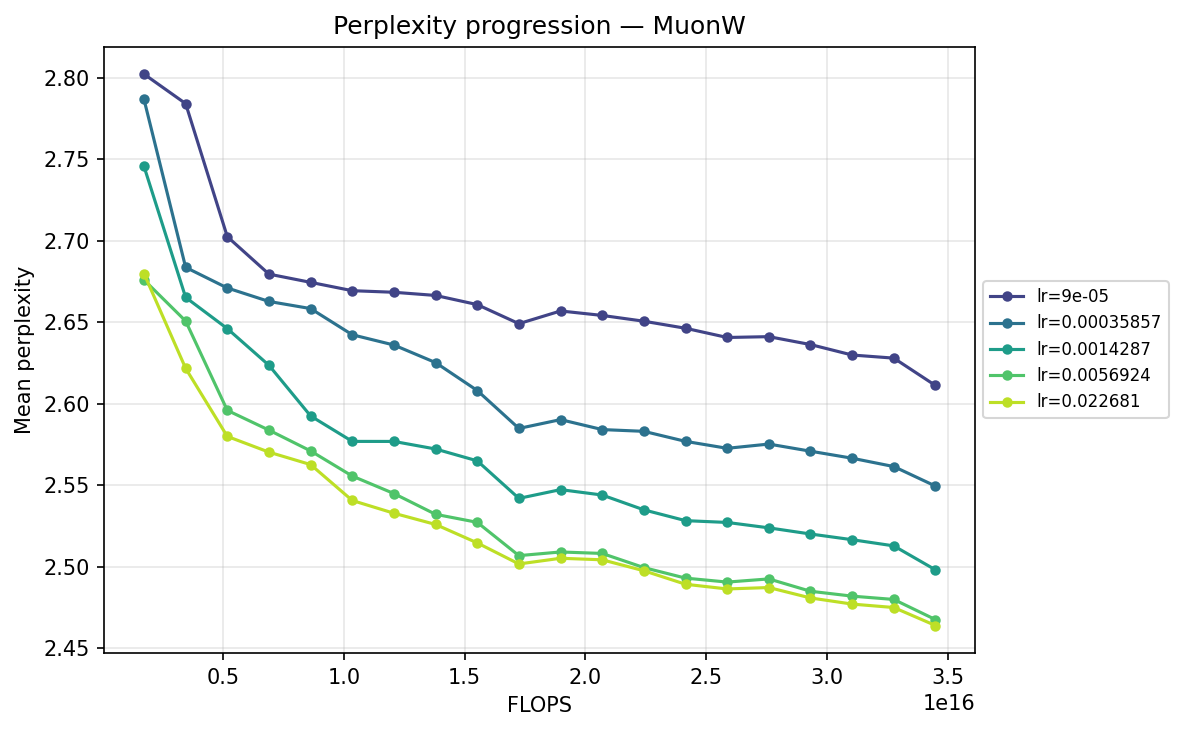
MuonW
Viewing the optimizers individually clarifies these dynamics. For AdamH, the intermediate learning rate ∼\(5.69 \times 10^{-3}\) (yellow) provides the steepest drop and lowest final perplexity (∼2.48). Exceed this, and it destabilizes; fall short, and it converges too slowly. AdamW is far more forgiving across learning rates: at \(\approx 3.59 \times 10^{-4}\), it settles into a remarkably smooth, steady decline to its lowest perplexity of ∼2.51. MuonH exhibits a narrow but highly effective sweet spot at mid-range LRs (∼\(1.43 \times 10^{-3}\) to ∼\(5.69 \times 10^{-3}\)), but is heavily penalized at the maximum rate. Finally, MuonW distinctly favors scale: its progression monotonically improves as the learning rate increases, with the highest LR (∼\(2.27 \times 10^{-2}\)) driving the lowest perplexity overall.
Time-to-target: FLOP efficiency
We can quantify optimization efficiency by measuring the training FLOPs required to cross a specific validation target. We use a target of 2.51, the lowest perplexity reached by an optimizer candidate (specifically AdamW). MuonW at its optimal learning rate crosses this threshold by checkpoint 12, while AdamH at its optimal configuration only reaches it around checkpoint 19. This means MuonW reaches the target in roughly 37% fewer steps (and 37% fewer training tokens). Because the forward and backward passes dominate per-step FLOPs, Muon’s SVD-based update adds only a small overhead relative to the total step cost, so the 37% step reduction translates to a comparable reduction in total training FLOPs.
Training Dynamics
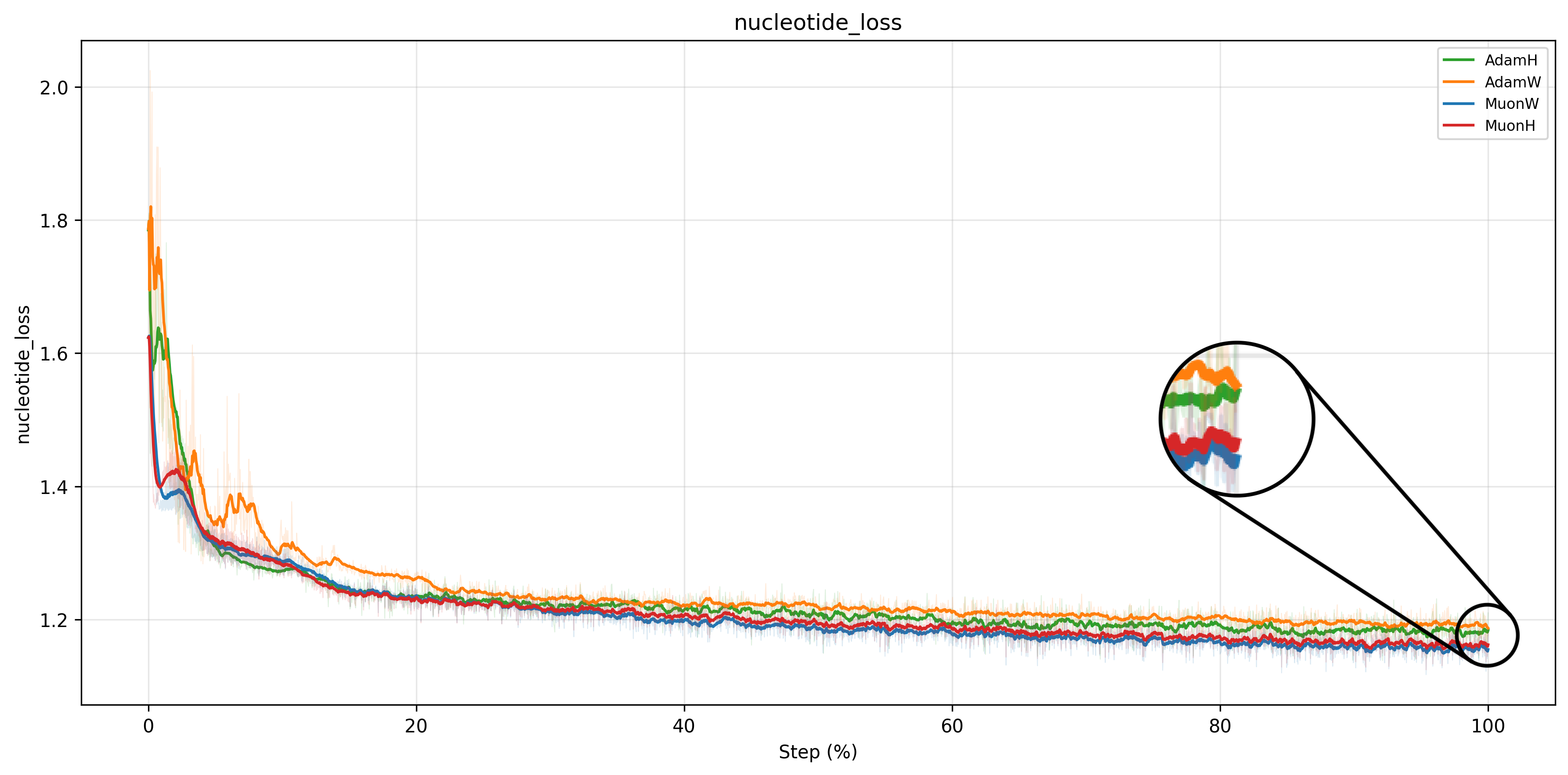
Consistent with existing literature210, Muon achieves a lower train loss than Adam across all configurations. The loss curves confirm the ranking established by the validation perplexity above: MuonW converges fastest and reaches the lowest loss, followed by MuonH, AdamH, and AdamW.
Learning rate sweep analysis
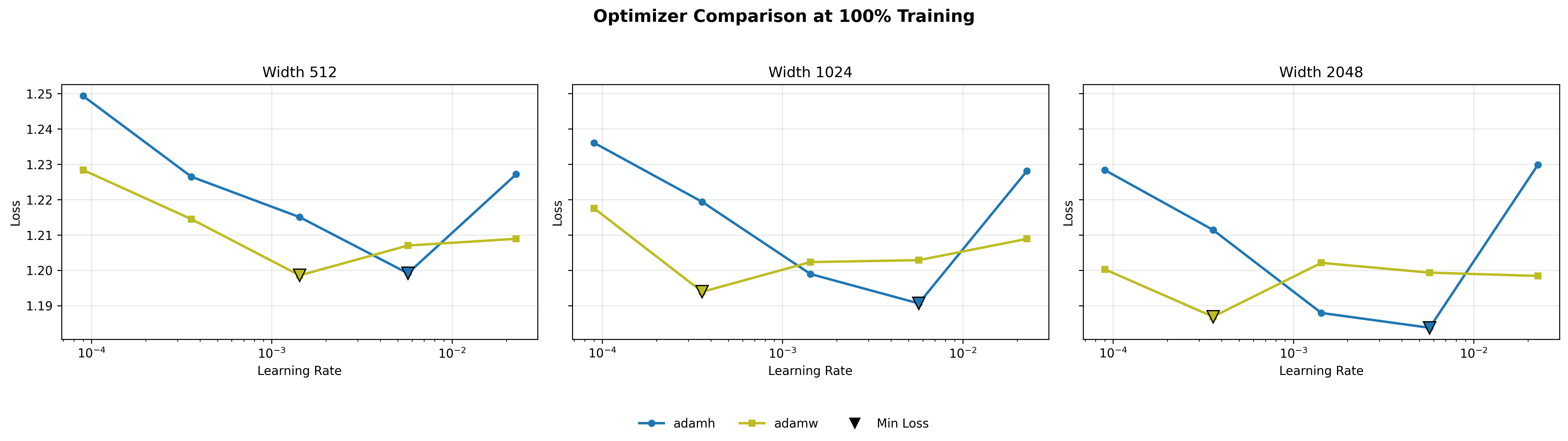
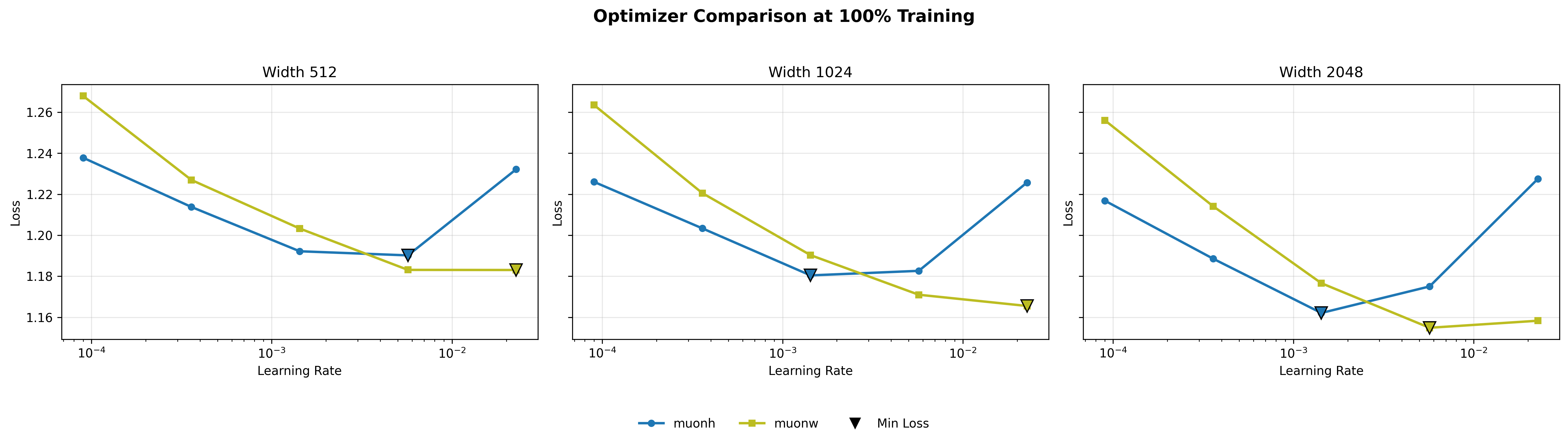
What is striking about these sweep curves is how consistent their structure is across scales. For Adam, Hyperball (blue) carves out a partial convex basin in the mid learning rate range (\(\sim 10^{-3}\) to \(10^{-2}\)), dipping below weight decay (yellow) in that region and rising above it at both extremes. This shape persists across widths, suggesting that Hyperball’s norm control is genuinely helpful in Adam’s optimal operating range. For Muon, the pattern is different: MuonW’s (yellow) loss decreases roughly linearly with increasing step size, while MuonH (blue) curves downward then upward more sharply. MuonW reaches a lower minimum at a higher learning rate. This near-linear response for MuonH also holds across scales, hinting that Hyperball’s fixed-norm constraint limits how much Muon can exploit larger step sizes.
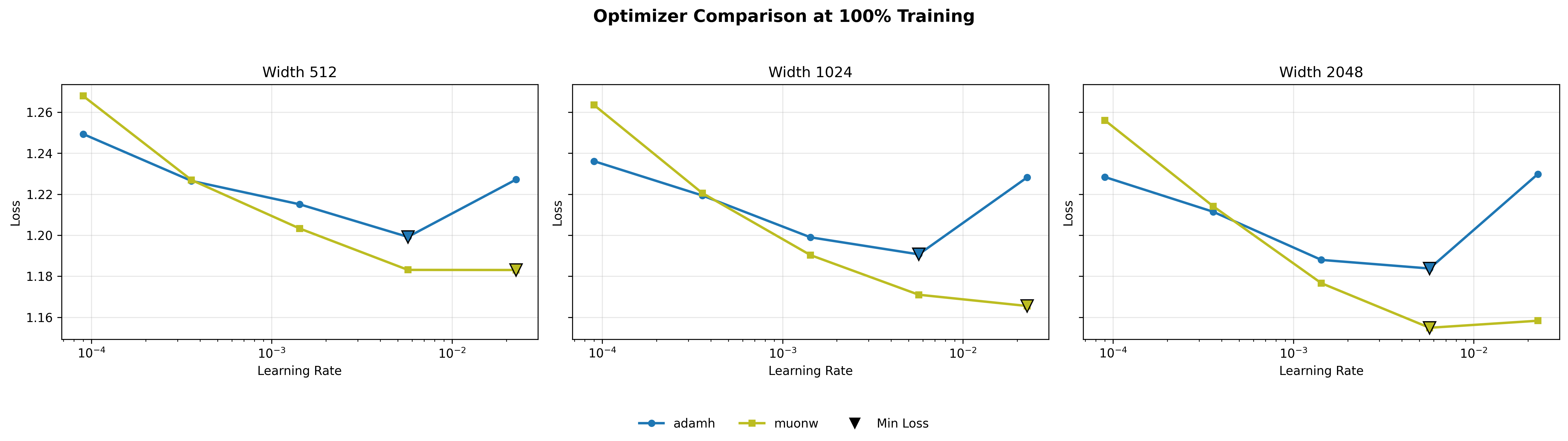
For Adam, the lowest point is with Hyperball at \(\eta \approx 5.69 \times 10^{-3}\) (compared to AdamW at \(\approx 3.59 \times 10^{-4}\)). For Muon, the lowest point is generally achieved with weight decay at the higher end of tested learning rates, scaling up to \(\eta \approx 2.27 \times 10^{-2}\) (although Hyperball reaches its optimum earlier at \(\eta \approx 1.43 \times 10^{-3}\)). This disparity highlights a key distinction: while Adam's coordinate-wise updates become highly unstable at large learning rates, Muon's whitened updates, when unconstrained by a fixed norm, can safely exploit much larger step sizes to drive down the loss.
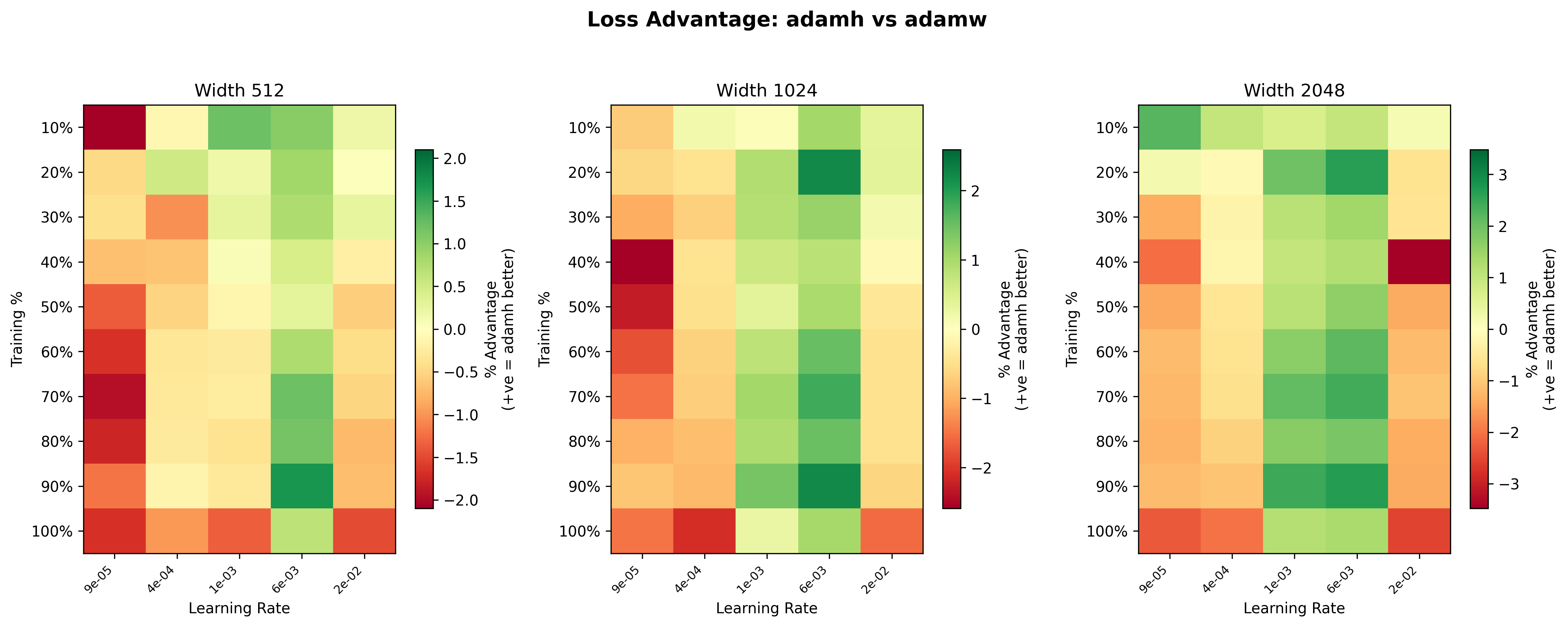
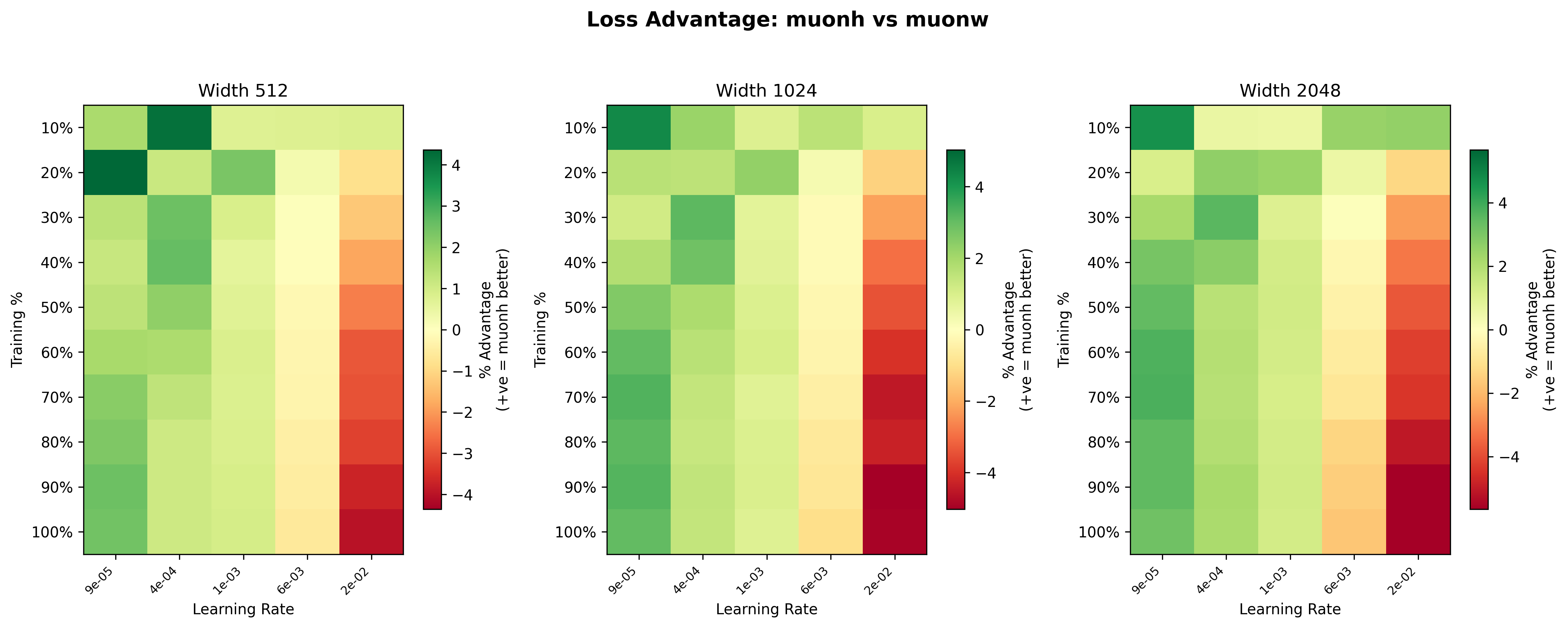
These heatmaps11Each heatmap uses its own color scale, so the same shade of green or red can represent different magnitudes across panels. Pay attention to the individual legends. give us a clearer picture of where Hyperball (blue) has the advantage over weight decay (yellow). For Adam, the advantage is scale-dependent: at width 512, the heatmap is mostly yellow (roughly even), but at width 2048, AdamH shows a noticeably stronger advantage, with greener squares across much of the grid. In particular, the mid learning rate range (\(\sim 10^{-3}\) to \(6\times 10^{-3}\)) is consistently green across widths, suggesting Hyperball’s norm control is most beneficial at moderate step sizes. At the highest learning rate (\(2.27\times 10^{-2}\)), weight decay dominates, likely because the effective step size grows too large (it grows \(\propto\eta\)) and training can never stabilize.
For Muon, the scale dependence runs in the opposite direction. At width 512, Hyperball is competitive or slightly ahead across much of the grid, with light green dominating the mid learning rates. By width 1024, the advantage fades to mostly yellow, and at width 2048 the picture inverts: the heatmap is mostly warm, with weight decay winning by up to ~4.5% at the higher learning rates late in training. This suggests that the spectral squeeze (described in the Spectral Analysis) worsens with scale; larger weight matrices have more trailing singular directions for the uniform rescaling to erode.
Cross-optimizer comparison
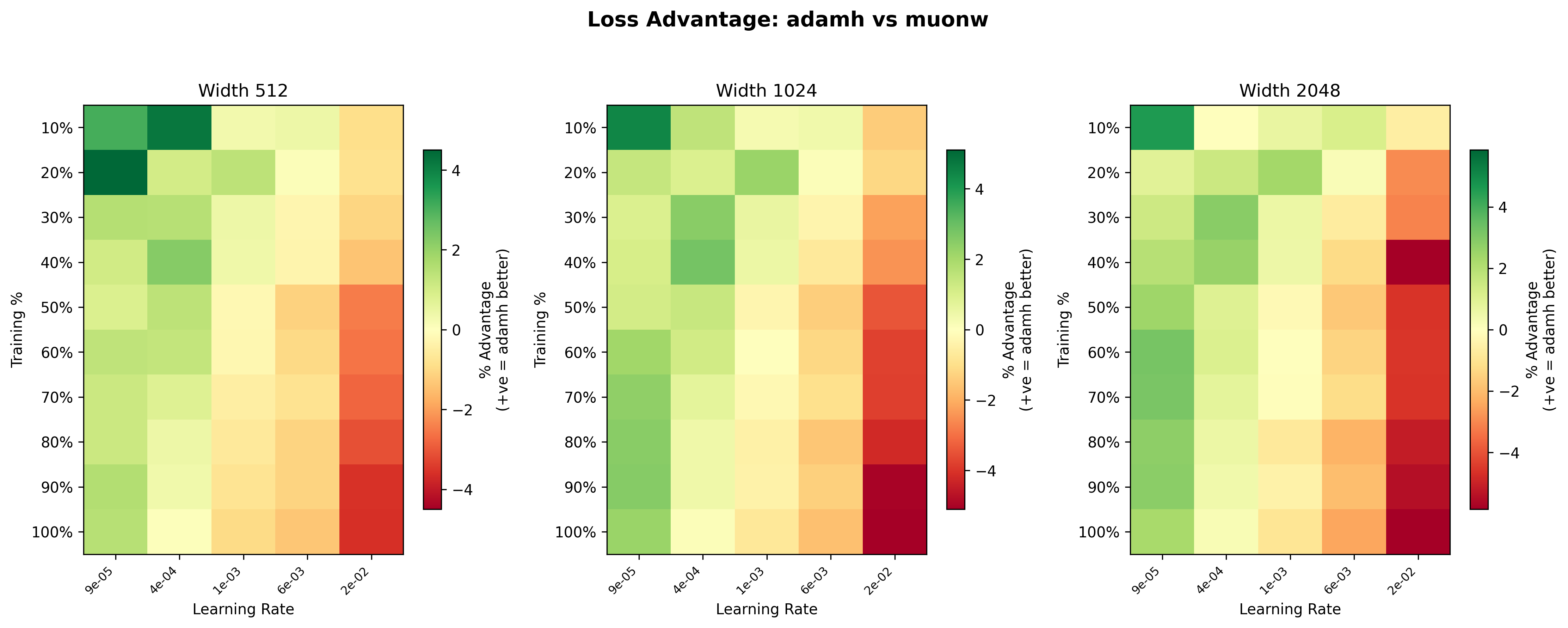
Finally, we compare the two best configurations head-to-head: MuonW against AdamH. Even at width 512, MuonW eventually pulls away; the curves track each other at lower learning rates, but MuonW pulls away at higher learning rates. What changes with scale is consistency: at width 1024 and especially 2048, AdamH holds the advantage across the broader low/mid range, while MuonW dominates the high learning rate extremes by a massive margin. The loss curves reinforce this: the gap between blue and yellow widens at higher learning rates and persists more uniformly at larger widths, suggesting that the performance gap increases with width, consistent with a spectral mechanism discussed below.
Spectral Analysis
To understand why Muon with independent weight decay (MuonW) outperforms its constrained counterpart (MuonH), we can gain insight by examining the spectral properties of the learned representations. Rather than examining the spectral norm itself (since the exact multiplier is less important given scale invariance), we focus on the distribution of singular values. Following the eigenspectral framework of NerVE1512NerVE originally applies these metrics to track activation dynamics through FFN layers, but the same spectral measures are equally well defined for weight matrices., we track two key metrics for the weight matrices:
- Spectral Entropy: A measure of how uniformly variance is distributed across singular values. Values near \(1.0\) indicate a "full rank", diverse representation, while values near \(0\) indicate rank collapse (variance concentrated in a few dimensions).
- Participation Ratio (PR): The effective rank of the matrix. Higher PR means more active dimensions are used to represent data. We normalize the PR to get the ratio of the effective rank to full rank, which allows us to compare matrices of different shapes (we want to see the training dynamics, exact scale is not important).
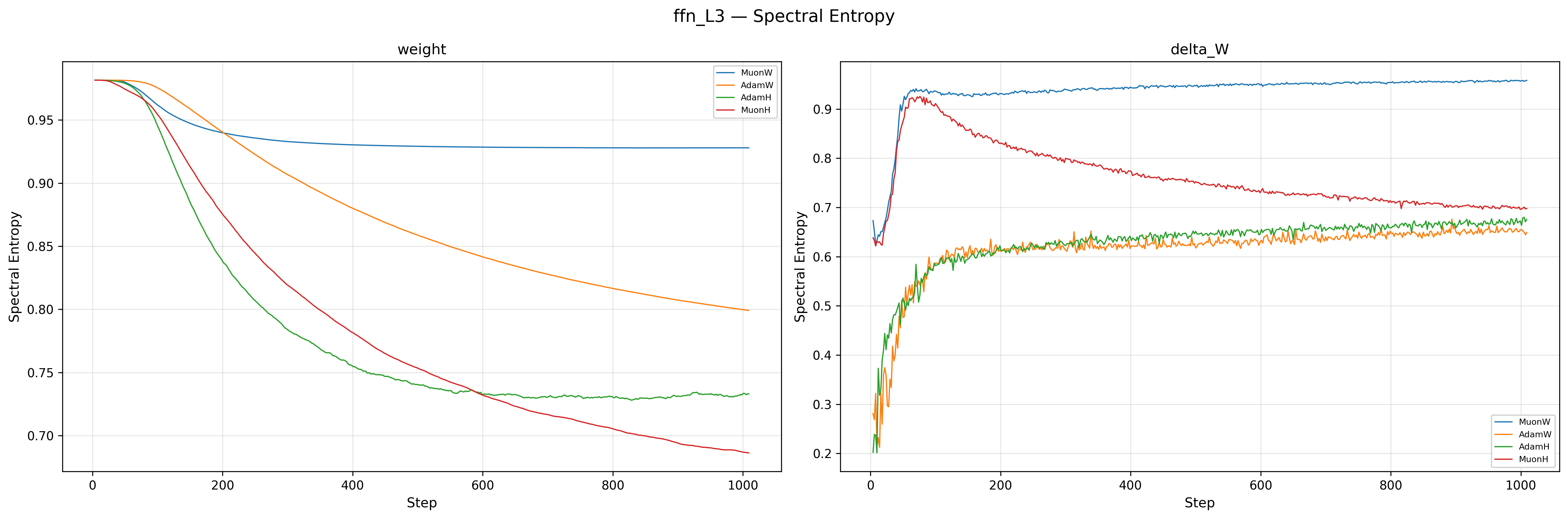
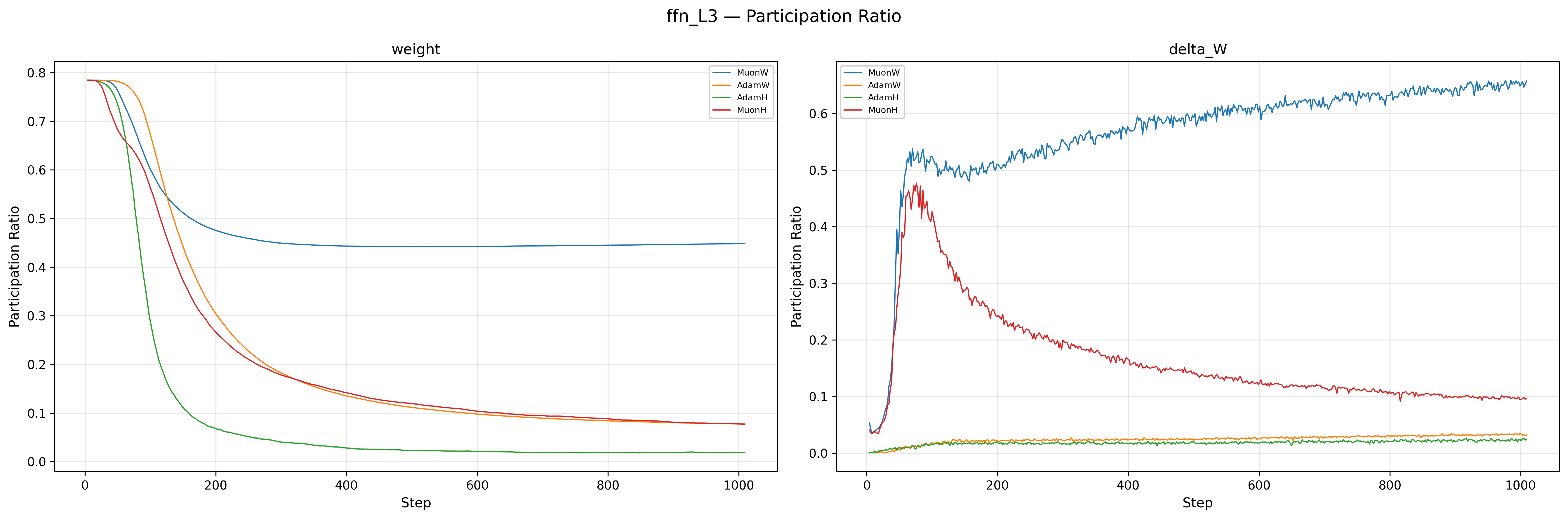
The weights of MuonW (Blue) and MuonH (Red) both start with high spectral entropy (\(\approx 0.98\)), but their trajectories diverge sharply. MuonW’s entropy decreases only slightly and stabilizes near \(\approx 0.93\), indicating that the weight matrices maintain a near-uniform singular value distribution throughout training; this is consistent with whitened updates supporting a more distributed spectral structure. MuonH (Red), by contrast, steadily collapses from \(\approx 0.98\) to \(\approx 0.68\), with the participation ratio falling in tandem: the effective rank of the weight matrices shrinks over training, a strong rank/entropy collapse signature that could indicate representational degeneration16. The Adam variants (Orange, Green) sit relatively lower for delta_W, which is expected since Adam does not whiten its updates. The critical observation is the divergence between Blue and Red: both use the same Muon whitening, yet MuonH’s spectrum degrades while MuonW’s does not. This is strongly consistent with the Hyperball constraint driving the degradation. The \(\Delta W\) entropy tells a consistent story: MuonW’s updates rise and stabilize near \(\approx 0.95\), while MuonH’s updates peak early and then become progressively less whitened (dropping from \(\approx 0.92\) to \(\approx 0.7\)), consistent with a feedback loop from the weights into the updates.
Why isn't Muon's \(\Delta W\) always full-rank with entropy 1?
One might expect Muon's whitening step to produce a perfectly uniform spectrum, but in practice the Newton-Schulz iterations used to approximate the polar factor are finite (typically 5 iterations), pushing singular values only toward 1 rather than exactly to 1 (roughly into \([0.7, 1.3]\)). More importantly, if the underlying momentum matrix has near-zero singular values (which is common when the batch gradient signal lies in a low-dimensional subspace), finite iterations cannot lift those values appreciably. Additionally, our Nesterov momentum means NS\(_5\) whitens a lookahead lerp of the gradient and the momentum buffer, not the gradient at \(W_t\) itself, so the spectral structure of \(U_t\) already reflects a blended signal. Finally, note that \(\Delta W \neq U_t\): with independent weight decay, \(\Delta W = W_{t+1} - W_t = U_t - \lambda W_t\), so the actual weight change includes a decay term \(-\lambda W_t\) whose spectral structure is that of the current weights, not the whitened update. Even if \(U_t\) were perfectly whitened, \(\Delta W\) would still inherit the spectral bias of \(W_t\).
Uniform Rescaling and the Spectral Squeeze
MuonH (Red) constrains \(\|W\|_F = R\) at every step by multiplying every singular value by the same factor \(c = R/\|W_t + U_t\|_F\). The large singular values survive this downscaling; the small ones (which Muon’s whitening tried to grow) cannot, because the uniform rescaling pulls them back down before they accumulate meaningful energy. Over many steps this concentrates the spectrum into fewer dominant modes, erasing the weak regulatory signals in the tail.
This effect is compounded on the update side. Recall that Muon’s NS\(_5\) whitening is imperfect: it pushes singular values toward \(1\) but lands in roughly \([0.7, 1.3]\), not exactly at \(1\). For MuonW (Blue), these small imperfections are benign; the weight matrix is free to absorb them, and the \(\Delta W\) spectral entropy stays high (\(\approx 0.95\)) throughout training. For MuonH (Red), one plausible mechanism is a feedback loop: as the weight spectrum collapses, the gradients computed at \(W_t\) become increasingly anisotropic, which flows into the momentum buffer. Imperfect NS\(_5\) whitening may be insufficient to fully recover a uniform spectrum from this biased input, so the update itself becomes progressively less whitened. In the \(\Delta W\) entropy plot, MuonH (Red) starts near MuonW (Blue) but steadily diverges, dropping to \(\approx 0.7\) by the end of training, consistent with this hypothesized mechanism.
In contrast, MuonW (Blue) imposes no hard constraint on the weight norm, so there is no uniform rescaling step and no feedback loop. Muon’s whitened updates can grow the small singular directions over many steps without them being pulled back, and the dominant singular directions can grow without suppressing the smaller ones. MuonW shows sustained higher spectral entropy and participation ratio, suggesting a more distributed use of singular directions; we hypothesize this helps increase capacity and retain combinatorial regulatory structure.
Note on Adam
AdamW (Orange) maintains high entropy (relative to AdamH and MuonH), potentially because coordinate-wise updates can sustain activity in smaller singular directions by injecting noise. MuonW achieves high entropy through 'clean' whitened updates that amplify rare directions. This distinction aligns with NerVE's15 finding that stable spectral signatures correlate with generalization ability and respond predictably to optimizer design choices.
Implicit Annealing and Relative Step Size
The second piece of the puzzle lies in the relative step size. We define the relative step size as \(\frac{\|\Delta W\|}{\|W\|}\).
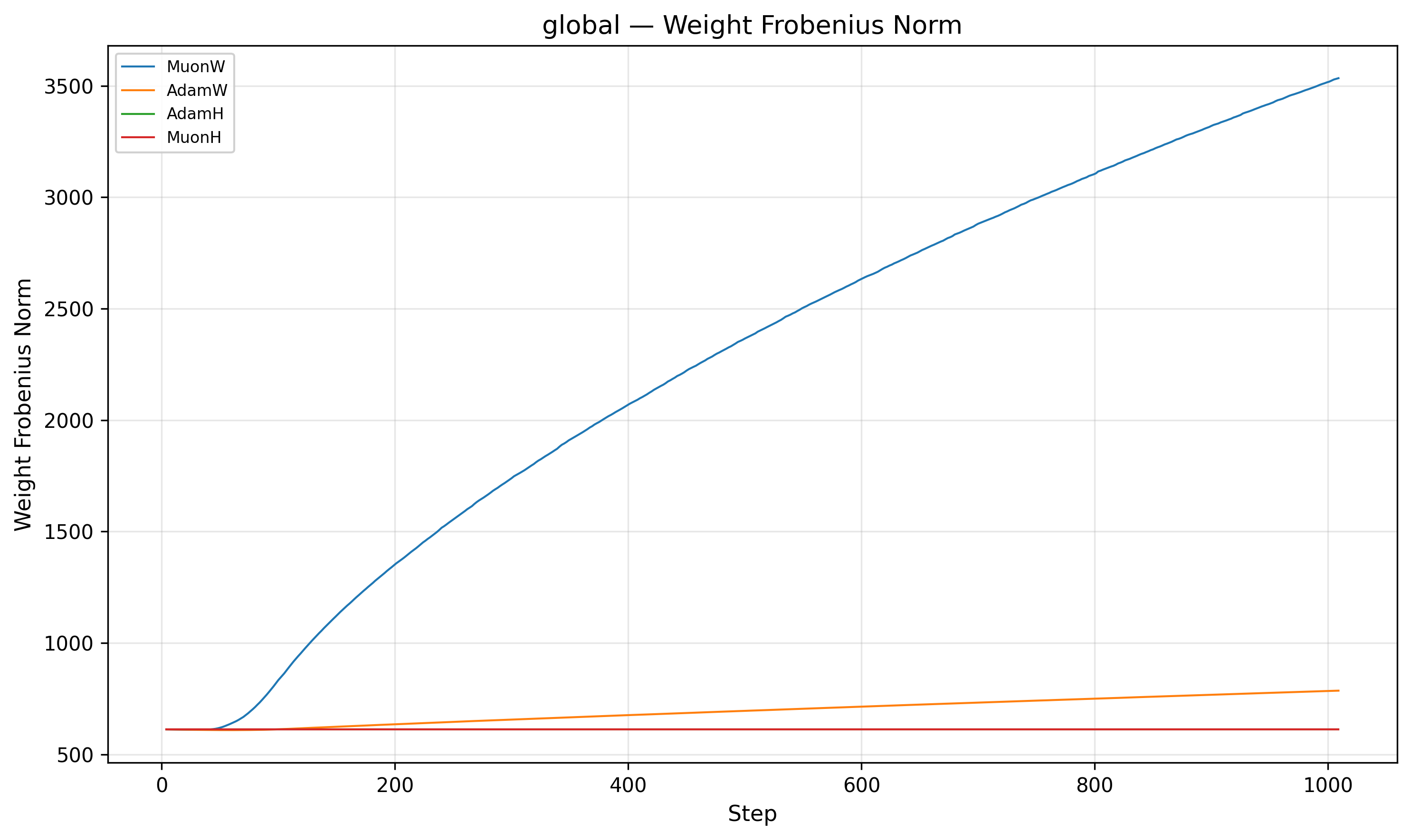
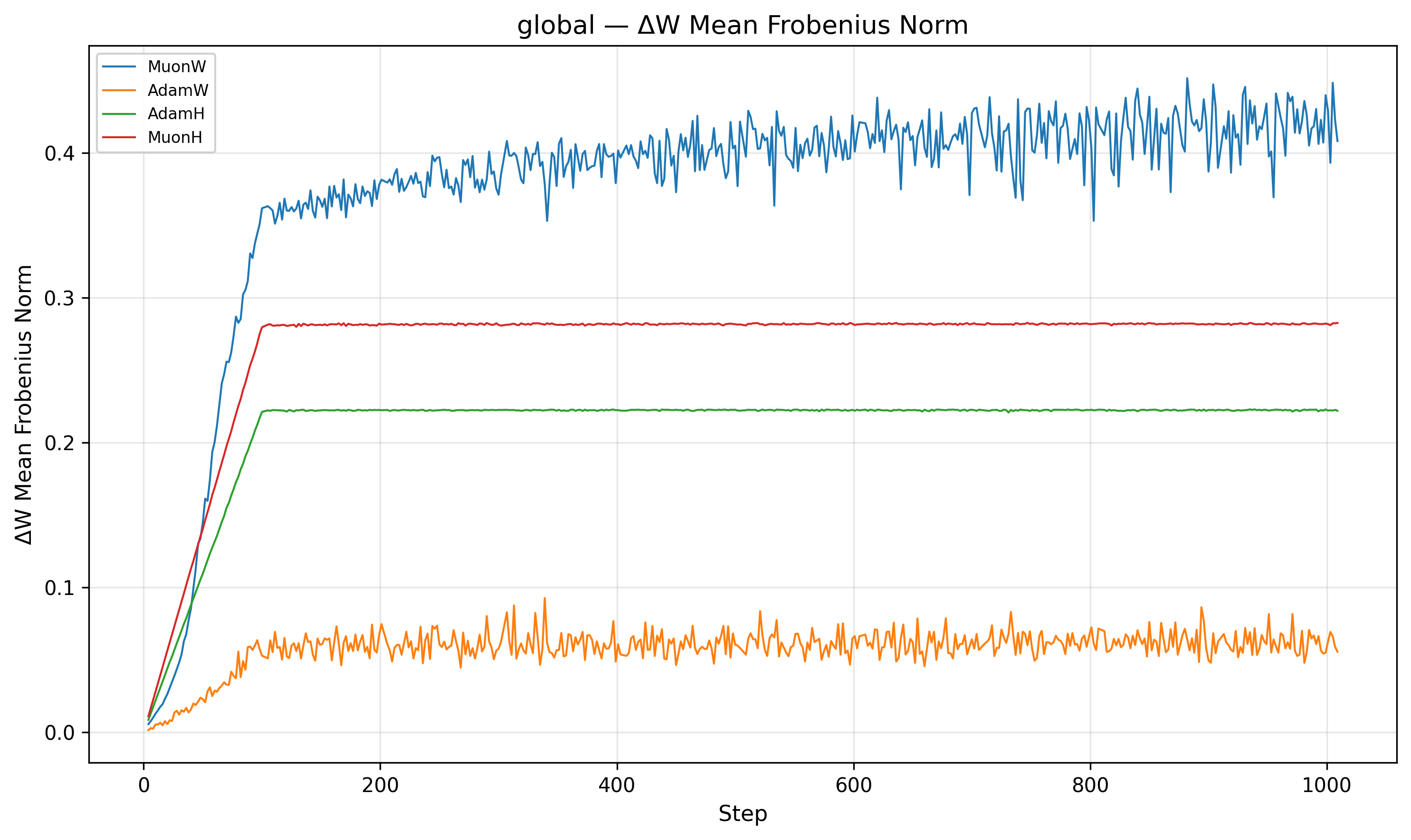
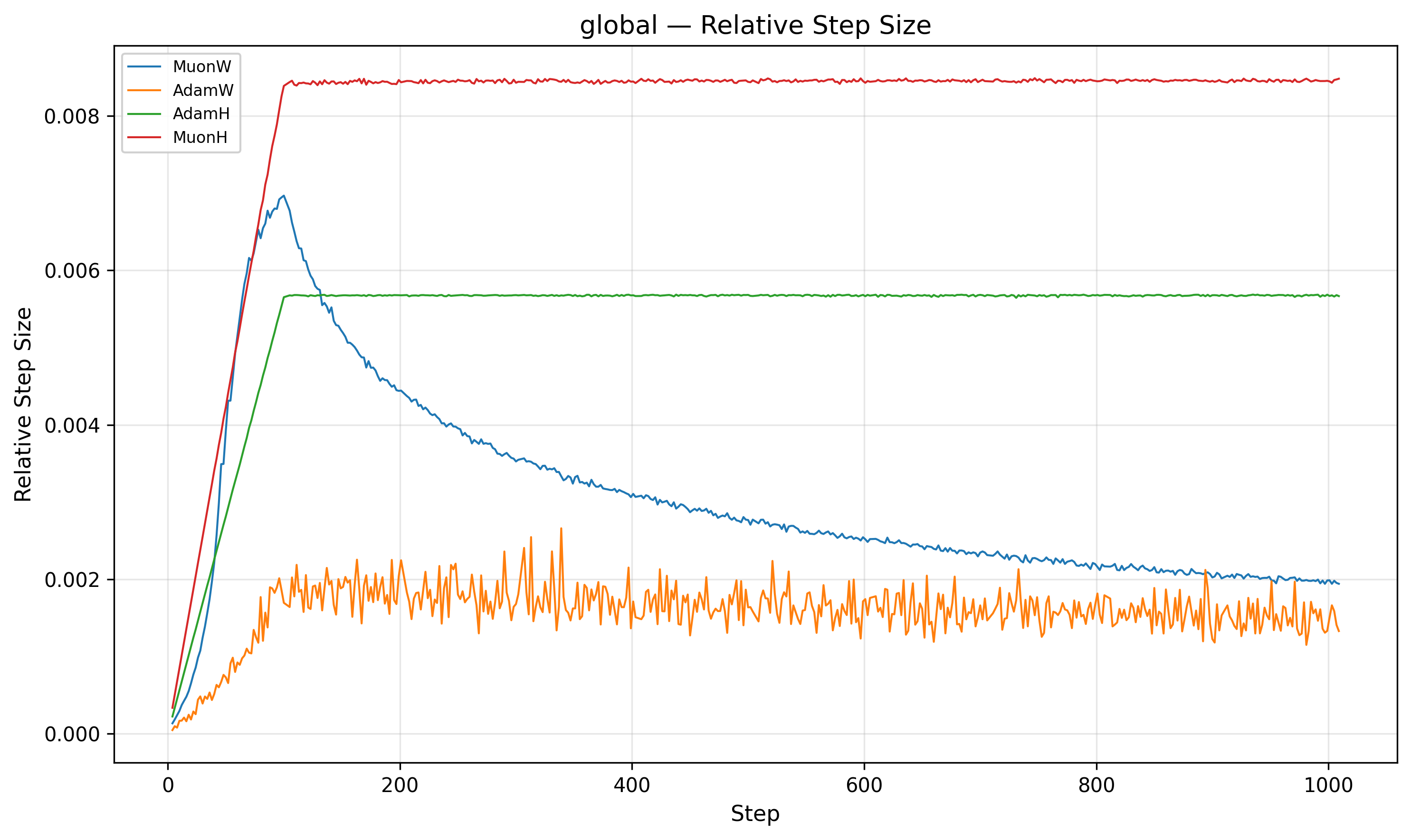
Indeed, MuonW's (Blue) weight norm grows monotonically throughout training. The update norm \(\|\Delta W\|\) is roughly constant post-warmup (it increases very slightly), but the weight denominator \(\|W\|\) balloons. Although independent weight decay should theoretically bound the norm at an equilibrium9, 10, the norm continues to grow long after the nucleotide loss has begun to plateau. This causes the relative step size to decrease over training (driven mainly by weight norm growth), which may act like an implicit annealing schedule that helps the model refine its solution in later stages.
For MuonH (Red), the weight norm \(\|W\|\) is fixed. The relative step size flattens out and never decays. MuonH’s relative step size stays roughly constant; we suspect this limits fine-grained convergence by preventing late-stage refinement.
Activation Hacking: The Logit Inflation "Cheat"
There is an alternative, less flattering interpretation of MuonW's success: fit the cross-entropy loss by simply inflating the logits. In classification tasks, the cross-entropy loss can be decreased by sharpening the probability distribution (making the model more "confident"), even if the ranking of classes doesn't change.
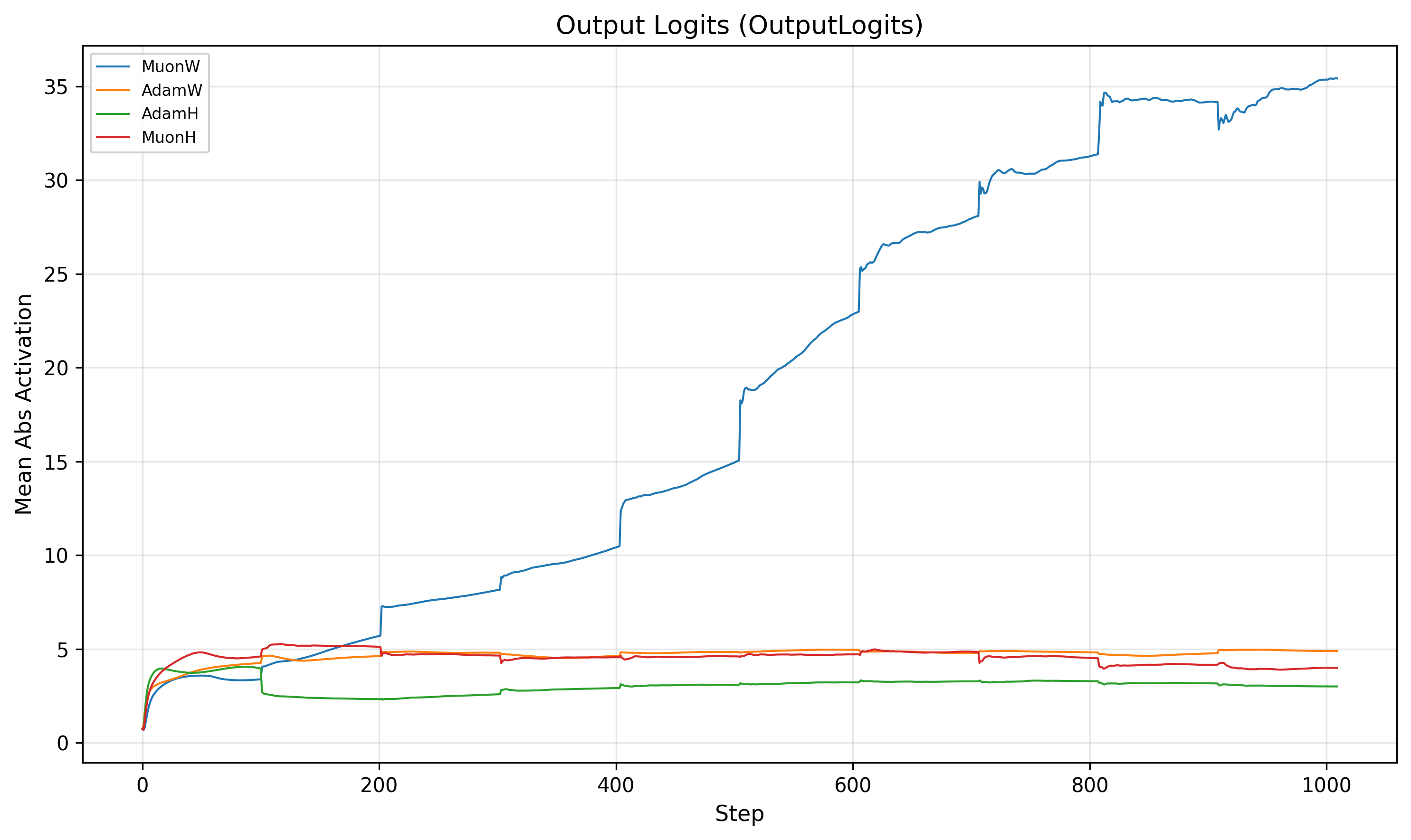
As noted above, MuonW's weight norm grows monotonically throughout training. While the RMSNorm-sandwiched hidden layers are scale invariant (Appendix F), the final output projection is not. There is no normalization between the last linear layer and the softmax. This means the runaway norm growth could potentially inflate the magnitude of the output logits, sharpening the softmax distribution and pushing the model toward higher confidence predictions.
This acts exactly like lowering the softmax temperature. Whether this
"activation
hacking" helps or hurts depends on the task. DNA has a vocabulary of just 4 bases, and
in
regulatory regions the correct nucleotide often dominates its context window. Sharper
predictions on a tiny, low entropy vocabulary are frequently correct, so inflated logits
often reduce cross-entropy loss in this setting. Natural language, by contrast, has a
vocabulary of ~100k tokens with genuinely ambiguous contexts where probability mass must
be
spread across many plausible continuations15
Quantitatively, consider the softmax function \(\sigma(\mathbf{z})_i =
\frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}}\). If we multiply the logits by a large
factor \(k\), the terms become \(e^{k z_i}\). Since the exponential function
grows incredibly fast, even a small difference in raw logits becomes a massive
difference after exponentiation. The largest logit \(z_i\) will dominate the sum
in the denominator, pushing the probability \(\sigma(\mathbf{z})_i\) towards
1 (provided \(k\) is large enough).
For DNA (\(K=4\)), there are only 3 other terms in the denominator to compete
with. Even a small lead for the correct nucleotide allows it to overwhelm the
others; let \(k_{DNA}\) be the minimal such multiplier. For NLP (\(K \approx
100,000\)), the denominator sums over 100,000 other
terms. Even if each is small, their total mass is significant, acting as a
"drag" that prevents the correct token from dominating the distribution purely
through scaling by \(k_{DNA}\).
.
This means that part of MuonW's training loss advantage may be an artifact of the domain: the optimizer exploits the low cardinality and low entropy of the DNA vocabulary to "hack" the loss via logit scaling, rather than learning richer internal representations. In fact, MuonW's validation perplexity also clearly improved, which can also be explained by logit inflation! MuonH (Red), with its strict norm constraint, is mathematically forbidden from using this trick, which may partially explain its higher training loss despite learning a "cleaner" low-rank representation. Disentangling this effect from the genuine spectral capacity gains discussed above is an important open question, and one that a controlled comparison with a fixed norm output head could help resolve.
Why don’t AdamW’s logits grow?
Adam’s update for each parameter is proportional to \(m_t / \sqrt{v_t}\), where \(m_t\) is the gradient EMA and \(v_t\) the EMA of squared gradients. In DNA modeling, where batches are likely dominated by shifting, independent 6–20bp motifs, the gradients could fluctuate significantly from step to step. The first moment \(m_t\) may suffer destructive interference as positive and negative gradients cancel, while the second moment \(v_t\), which averages strictly positive squared values, would not suffer from sign cancellation and could remain relatively stable and large. This would cause the ratio to shrink, making Adam’s steps progressively smaller. Increasing the learning rate may not help: a larger \(\eta\) would amplify noisy, unstructured coordinate-wise updates, potentially destabilizing training, as the charts above suggest (see how fast losses rise for the largest learning rate).
Muon may sidestep this issue. Its Newton–Schulz whitening discards the per-element scale and forces a fixed-norm update at every step, so temporal noise would not suppress the step size. This could explain why MuonW is able to push larger updates through the output projection, overcoming weight decay to inflate logits, while AdamW may be constrained by its own variance denominator.
Next Steps
Thus, the results presented here reflect relative optimizer comparisons at a fixed compute budget, not the absolute frontier of model quality. Next, we plan to:
- Run the full sweep with SSO: repeat the Adam/Muon \(\times\) Hyperball sweeps using the Spectral Sphere Optimizer (SSO)18 to test whether controlling \(\sigma_1\) of the weight matrix directly improves stability and performance compared to Frobenius norm control.
- Explore hybrid optimizers: evaluate combinations of Muon and Adam updates (like PRISM19 and variants20) and compare against these results.
- Evaluate on biological downstream tasks: measure whether perplexity gains translate to improvements on tasks that matter for biology, such as transcription factor motif recovery, and sequence generation.
Appendices
Appendix A: Adam Overview
Let \(g_t = \nabla_W \mathcal{L}(W_t)\) denote the gradient at step \(t\). Adam maintains two exponential moving averages (EMAs):
- a first moment estimate (mean) \(m_t\),
- a second moment estimate (uncentered variance) \(v_t\).
Specifically, with hyperparameters \(\beta_1,\beta_2 \in [0,1)\) and initialization \(m_0 = 0\), \(v_0 = 0\):
\[ m_t = \beta_1 m_{t-1} + (1-\beta_1) g_t, \qquad v_t = \beta_2 v_{t-1} + (1-\beta_2) g_t^2, \]where \(g_t^2\) denotes elementwise squaring.
Because both EMAs start at zero, they are biased toward \(0\) early in training. Adam, therefore, uses bias corrected estimates
\[ \hat m_t = \frac{m_t}{1-\beta_1^t}, \qquad \hat v_t = \frac{v_t}{1-\beta_2^t}. \]The vanilla Adam update is then,
\[ W_{t+1} = W_t - \eta\, \frac{\hat m_t}{\sqrt{\hat v_t}+\varepsilon}, \]with learning rate \(\eta\) and small \(\varepsilon > 0\) for numerical stability.
Weight decay (AdamW)
Soft L2 regularization can be implemented by adding \(\lambda W_t\) to the gradient, but
AdamW instead decouples weight decay from the adaptive gradient step. In its common
form:
so weight decay shrinks parameters directly (multiplicatively), while the Adam step uses the adaptive per parameter scaling.
Independent weight decay
In our setting, we use independent weight decay: the shrinkage is applied as a
separate step, not through the gradient, and is not tied to the learning rate.
Concretely, if \(U_t\) denotes the optimizer's proposed parameter update (e.g., the Adam step \(U_t=-\eta\, \hat m_t/(\sqrt{\hat v_t}+\varepsilon)\)), then independent weight decay applies
\[ W_{t+1} = (1-\lambda)\,W_t + U_t. \]So the decay rate \(\lambda\) is not multiplied by the learning rate and can be scheduled separately.
Appendix B: SVD Overview
Singular value decomposition (SVD)
For any real matrix \(A \in \mathbb{R}^{m\times n}\), the SVD factorizes \(A\) into
where \(U\in\mathbb{R}^{m\times m}\) and \(V\in\mathbb{R}^{n\times n}\) are orthogonal matrices (their columns form orthonormal bases), and \(\Sigma\in\mathbb{R}^{m\times n}\) is diagonal (rectangular) with nonnegative entries \(\sigma_1\ge \sigma_2\ge \cdots \ge 0\) called the singular values. Geometrically, \(V^\top\) rotates (or reflects) the input space, \(\Sigma\) scales along the orthogonal axes, and \(U\) rotates (or reflects) the output space.
What are singular values?
The singular values of matrix \(A\) are the square roots of the eigenvalues of \(A^\top A\)
(or equivalently, of \(AA^\top\) if \(A\) is square). Concretely, for eigenpairs \((\lambda_i, v_i)\) of
\(A^\top A\),
\[
A^\top A v_i = \lambda_i v_i, \qquad \sigma_i = \sqrt{\lambda_i}.
\]
They quantify how much \(A\) stretches vectors: along the right singular direction
\(v_i\), the mapping scales by exactly \(\sigma_i\). Geometrically, the largest singular
value is the maximum stretch induced by \(A\) on any unit vector:
\[
\sigma_1 = \max_{\|x\|=1}\|Ax\|.
\]
Note that \(\sigma_2\) is the maximum stretch induced orthogonal to \(v_1=\arg\max_{\|x\|=1}\|Ax\|\), or \(\sigma_2=\max_{x\perp v_1:\:\|x\|=1}\|Ax\|\), and \(\sigma_3\) has the stretch orthogonal to the first 2, and so on16For completeness, we can generalize this idea either recursively (where we define \(\sigma_i\) as the max stretch orthogonal to \(v_j\) \(\forall j \lt i\)), or succinctly using the Min max theorem: \(\sigma_i=\min_{U\subseteq \mathbb R^n:\:\dim (U)=n-i+1}\max_{x\in U:\:\|x\|=1}\|Ax\|\), where \(n\) is the dimension of the domain (number of columns)..
Why are they special?
They control several important properties at once:
- Spectral norm/stability: The spectral norm is defined as \(\|\cdot\|_2=\sigma_1(\cdot)\) on matrix inputs. It is the operator norm17Formally, the operator norm \(\|\cdot\|_p\) is defined for \(A\in \mathbb R^{m\times n}\) as \(\|A\|_p=\max\{\|Ax\|_p:x\in \mathbb R^n, \|x\|_p\le 1\}\), where we apply the \(\ell_p\) norm to the vectors. induced by the vector \(\ell_2\) norm. As previously mentioned, \(\sigma_1(A) = \|A\|_2\) is the maximum amplification (or stretch) of \(A\); this is important for Lipschitz bounds, which are a common assumption behind stability and generalization arguments in ML12.
- Rank / effective dimension: the number of nonzero \(\sigma_i\) equals \(\mathrm{rank}(A)\); many tiny \(\sigma_i\) indicates a nearly low rank map.
- Conditioning: the ratio \(\sigma_1/\sigma_r\) (for \(\sigma_r = \min_{\neq 0}\sigma_i\)) measures how unevenly \(A\) scales different directions; large ratios typically mean some directions learn/propagate signal much more strongly than others, which can hurt optimization and numerical stability.
Appendix C: Concentration of measure in the hyperball
Let \(B_n(R)=\{x\in\mathbb{R}^n:\|x\|\le R\}\) be the Euclidean \(n\)-ball of radius \(R\), and let \(0 \lt \varepsilon \lt R\). Define the outer shell \[ S_{n}(R,\varepsilon)=\{x\in\mathbb{R}^n: R-\varepsilon \le \|x\|\le R\}. \] Then the fraction of volume in the shell satisfies \[ \frac{\mathrm{Vol}(S_{n}(R,\varepsilon))}{\mathrm{Vol}(B_n(R))} = 1 - \left(1-\frac{\varepsilon}{R}\right)^{n} \xrightarrow[n\to\infty]{} 1. \] Equivalently, the “interior” ball \(B_n(R-\varepsilon)\) contains an asymptotically negligible fraction of the total volume.
Proof. The volume of an \(n\)-ball scales like \(R^n\): there is a constant \(c_n=\mathrm{Vol}(B_n(1))\) such that \[ \mathrm{Vol}(B_n(R)) = c_n R^n. \] Therefore, the shell volume is \[ \mathrm{Vol}(S_n(R,\varepsilon)) = \mathrm{Vol}(B_n(R)) - \mathrm{Vol}(B_n(R-\varepsilon)) = c_n(R^n-(R-\varepsilon)^n). \] Dividing by \(\mathrm{Vol}(B_n(R))=c_nR^n\) gives \[ \frac{\mathrm{Vol}(S_n(R,\varepsilon))}{\mathrm{Vol}(B_n(R))} = 1-\left(\frac{R-\varepsilon}{R}\right)^n = 1-\left(1-\frac{\varepsilon}{R}\right)^n. \] Since \(0\lt 1-\varepsilon /R\lt 1\), the term \((1-\varepsilon/R)^n\to 0\) as \(n\to\infty\), so the ratio tends to \(1\).
Suppose the equilibrium norm is \(N\), and the norm ‘hovers’ within just \(0\lt\varepsilon\ll N\) of this equilibrium, taking values in \([N-\varepsilon, N+\varepsilon]\). If we set \(R = N+\varepsilon\) and \(\delta = 2\varepsilon\), this range is exactly the shell \(S_n(R, \delta)\). As demonstrated above, no matter how small we make \(\varepsilon> 0\), the fraction of volume in this shell is \(1-\left(1-\frac{2\varepsilon}{R}\right)^n\), which still approaches \(1\) for large \(n\). Therefore, we will still have to consider a relatively large space of values near the equilibrium hypersphere (especially as the matrix dimension is roughly \(O(d^2)\) where \(d\) is the hidden size of the model).
Appendix D: Full derivation of the relative step size
The Hyperball retraction maps \(W_t + U_t\) back onto the hypersphere of radius \(R\). The geometry is captured by two triangles in the vectorized matrix space:
- Triangle \(O\text{-}A\text{-}B\): where \(O\) is the origin, \(A = W_t\) lies on the sphere, and \(B = W_t + U_t\) is the pre-retraction sum (generally off the sphere). Sides: \(\|OA\|=R\), \(\|AB\|=\eta R\), \(\|OB\|=c\). Interior angle at \(A\): \(\pi-\theta\).
- Triangle \(O\text{-}A\text{-}C\): where \(C = W_{t+1} = R\,\mathrm{Normalize}(W_t+U_t)\) is the retracted weight, also on the sphere. This is an isosceles triangle with \(\|OA\|=\|OC\|=R\), chord \(\|AC\|=x=\|\Delta W\|\), and apex angle \(\phi\).
The 2D diagram below labels all lengths and angles used in the derivation that follows.
We now derive the exact step size. Using the cosine rule on triangle \(O\text{-}A\text{-}B\) (where \(O\) is the origin, \(A = W_t\), and \(B = W_t + U_t\)), noting that the interior angle at \(A\) is \(\pi - \theta\):
\[ \begin{aligned} \text{Cosine rule on } \triangle OAB\!: \quad \|W_t+U_t\|^2 &= R^2 + \eta^2 R^2 - 2\eta R^2\cos(\pi-\theta) \\ &= R^2 + \eta^2 R^2 + 2\eta R^2\cos(\theta),\\ \text{Pre-retraction length: } c &:= \|W_t+U_t\| = R \sqrt{1 + \eta^2+ 2\eta \cos\theta}.\\ \end{aligned} \]Since \(W_{t+1}\) lies on the ray from \(O\) through \(B\), the angular change \(\phi := \angle(\vec W_t, \vec W_{t+1})\) equals \(\angle AOB\). Applying the sine rule to \(\triangle OAB\):
\[ \begin{aligned} \text{Sine rule: }\frac{\sin\phi}{\|U_t\|}&=\frac{\sin(\pi-\theta)}{\|W_t+U_t\|}\implies \sin\phi=\frac{\eta R}{c}\sin\theta=\frac{\eta R}{c}\sqrt{1-\gamma^2},\\ \implies \cos\phi&=\sqrt{1-\sin^2\phi}=\sqrt{1-\frac{\eta^2R^2(1-\gamma^2)}{c^2}} = \sqrt{1-\frac{\eta^2(1-\gamma^2)}{1+\eta^2+2\eta\gamma}}.\\ \end{aligned} \]Finally, \(W_t\) and \(W_{t+1}\) both lie on the sphere of radius \(R\), so we apply the cosine rule to the isosceles triangle \(\triangle OAC\):
\[ \begin{aligned} \text{Cosine rule on } \triangle OAC\!: \quad \|\Delta W\|^2 &= R^2+R^2-2R^2\cos\phi,\\ \text{Exact step size: } \quad x &:= \|\Delta W\| = R\sqrt{2}\sqrt{1-\cos\phi} = R\sqrt{2}\sqrt{1-\sqrt{1-\frac{\eta^2(1-\gamma^2)}{1+\eta^2+2\eta\gamma}}}. \end{aligned} \]Appendix E: Bounds on the relative step size
Now, suppose we know that \(\gamma,\eta\in(0,1)\). We can infer from this (using the interactive surface plot) that:
\[ \begin{aligned} &\min_{\gamma,\eta\in[0,1]} \frac{\eta^2-\gamma^2\eta^2}{1+\eta^2+2\eta\gamma} = 0 \implies \inf_{\gamma,\eta\in(0,1)} \frac{\eta^2-\gamma^2\eta^2}{1+\eta^2+2\eta\gamma} = 0 \\ &\arg\max_{\gamma,\eta\in[0,1]} \frac{\eta^2-\gamma^2\eta^2}{1+\eta^2+2\eta\gamma} = (0,1)\implies \sup_{\gamma,\eta\in(0,1)}\frac{\eta^2-\gamma^2\eta^2}{1+\eta^2+2\eta\gamma}=1/2\\ &\implies \frac{\eta^2-\gamma^2\eta^2}{1+\eta^2+2\eta\gamma}\in (0,1/2)\\ &\implies 1-\frac{\eta^2-\gamma^2\eta^2}{1+\eta^2+2\eta\gamma}\in (1/2,1)\\ &\implies \sqrt{1-\frac{\eta^2-\gamma^2\eta^2}{1+\eta^2+2\eta\gamma}}\in (1/\sqrt2,1)\\ &\implies 1-\sqrt{1-\frac{\eta^2-\gamma^2\eta^2}{1+\eta^2+2\eta\gamma}}\in (0,1-1/\sqrt2)\\ &\implies \sqrt{1-\sqrt{1-\frac{\eta^2-\gamma^2\eta^2}{1+\eta^2+2\eta\gamma}}}\in (0,\sqrt{1-1/\sqrt2})\\ &\implies x\in (0, R\sqrt2\sqrt{1-1/\sqrt2})=(0,R\sqrt{2-\sqrt2})\approx(0, 0.765R)\\ &\implies \frac{x}{\|W_t\|}\in (0,\sqrt{2-\sqrt 2})\approx (0, 0.765) \end{aligned} \]This is the tightest bound on the relative step size obtainable without knowledge of \(\gamma\). Computing \(\gamma\) analytically remains an open question, as the repeated retractions onto the hypersphere make it difficult to translate previous arguments involving momentum and weight decay10. Unfortunately, this bound is not particularly informative: the lower bound is vacuous, and the upper bound is substantially looser than the ideal \(O(\eta)\). Now, if, for instance, we input our tried and tested range ~\(\eta\in (10^{-4},10^{-1})\) and fix \(\gamma=0\), we get a slightly tighter bound of \((0.0001, 0.0996)\), where a higher learning rate corresponds to a higher step size. For a higher dot product like \(\gamma=0.5\), we get a bound of \((0.0000866, 0.0823)\), which is lower.
Appendix F: Enforcing scale invariance
A key ingredient is RMSNorm13, which rescales a vector by its root-mean-square (RMS) magnitude. Given an activation vector \(x\in\mathbb{R}^d\), RMSNorm computes \[ \mathrm{RMSNorm}(x) = g\odot \frac{x}{\sqrt{\frac{1}{d}\sum_{i=1}^d x_i^2 + \varepsilon}}, \] where \(g\in\mathbb{R}^d\) is a learned per coordinate gain, \(\varepsilon>0\) is for numerical stability, and \(\odot\) is the Hadamard product (element wise multiplication).
Rescaling property
Ignoring \(\varepsilon\) (or when \(\|x\|\) is not tiny), RMSNorm is scale
invariant: for any scalar \(\alpha>0\),
\[
\mathrm{RMSNorm}(\alpha x)= \mathrm{RMSNorm}(x).
\]
Intuitively, scaling the input by \(\alpha\) scales the denominator by the same
\(\alpha\), so the normalized direction stays the same.
Why this makes weight matrices scale invariant
Consider a linear map \(y = Wx\). If the model applies RMSNorm before the next
computation (pre-norm, post-norm, or both), then multiplying the weight matrix
by a
scalar often has little effect on the downstream activations:
\[
\mathrm{RMSNorm}((\alpha W)x) = \mathrm{RMSNorm}(\alpha (Wx)) =
\mathrm{RMSNorm}(Wx).
\]
So for these “RMSNorm sandwiched” layers, scale doesn't matter as
the
RMSNorm layer itself learns the scaling factor necessary for the output.
In Axis, our original model architecture, we used MuP initialization and layer pre-normalization, but that wasn't enough to enforce scale invariance in our model. To further enforce it, we added a layer post-norm and then QK-norm (like Gemma 3's architecture14), which seemed to be enough to enforce scale invariance (although, it seems like only adding the post-norm was sufficient for our model; the QK-norm was added for completeness).
References
- Loshchilov & Hutter. Fixing Weight Decay Regularization in Adam. arXiv 2017.
- Jordan et al. Muon: An optimizer for hidden layers in neural networks. 2024.
- Avsec et al. AlphaGenome: advancing regulatory variant effect prediction. bioRxiv 2025.
- Avsec et al. Effective gene expression prediction from sequence by integrating long range interactions. Nature Methods 2021.
- Brixi et al. Genome modeling and design across all domains of life with Evo 2. bioRxiv 2025.
- Chizat et al. On Lazy Training in Differentiable Programming. NeurIPS 2019.
- Jacot et al. Neural Tangent Kernel: Convergence and Generalization in Neural Networks. NeurIPS 2018.
- Jeremy Bernstein. The Modula Docs - Weight Erasure. 2025.
- Kosson et al. Rotational Equilibrium: How Weight Decay Balances Learning Across Neural Networks. ICML 2024.
- Wen et al. Fantastic Pretraining Optimizers and Where to Find Them II: From Weight Decay to Hyperball Optimization. 2025.
- Cesista. Muon and a Selective Survey on Steepest Descent in Riemannian and Non-Riemannian Manifolds. 2025.
- Bartlett et al. Spectrally-normalized margin bounds for neural networks. NeurIPS 2017.
- Zhang & Sennrich. Root Mean Square Layer Normalization. NeurIPS 2019.
- Gemma Team. Gemma 3 Technical Report. arXiv 2025.
- Jha & Reagen. NerVE: Nonlinear Eigenspectrum Dynamics in LLM Feed-Forward Networks. ICLR 2026.
- Gao et al. Representation Degeneration Problem in Training Natural Language Generation Models. ICLR 2019.
- Yang, Simon & Bernstein. A Spectral Condition for Feature Learning. arXiv 2023.
- Xie et al. Controlled LLM Training on Spectral Sphere. arXiv 2025.
- Yang. PRISM: Structured Optimization via Anisotropic Spectral Shaping. arXiv 2026.
- Cesista. Shampoo-PRISM: Kronecker-Factored Optimization via Anisotropic Spectral Shaping. 2026.
- Zach. The Concise Guide to Zipf’s Law. Statology.
- Piantadosi. Zipf’s word frequency law in natural language: A critical review and future directions. Psychonomic Bulletin & Review 2014.
- Wilson et al. The Marginal Value of Adaptive Gradient Methods in Machine Learning. NeurIPS 2017.
- Wolpert & Macready. No Free Lunch Theorems for Optimization. IEEE Trans. Evolutionary Computation 1997.